
画像生成AIの中でも、特に注目されているAI画像生成ツール「Stable Diffusion」。ここ数年、自身のPC上で使いこなす(ローカルで構築)方法が話題を呼んでいます。
オンラインサービスでStable Diffusionを使用すると、生成枚数の制限や課金の問題があり、「もっと自由に使いたい」「作品の幅を広げたい」といった悩みを抱えている方が多いです。
Stable Diffusionはローカル環境で使用すれば、制限なく使えるようになります。この記事では、Stable Diffusionのローカル環境構築の手順から基本的な使い方、高品質な画像生成のコツまで、初心者の方でも分かりやすく解説します。
GPUの性能を活かした高速生成や、自分だけのカスタマイズまで、あなたのAI画像生成の可能性を大きく広げる内容となっているので、ぜひ参考にしてください。
Stable Diffusionとは
Stable Diffusionは、テキストの説明から画像を生成できる最先端のAI画像生成モデルです。2022年に登場して以来、そのクオリティの高さと汎用性の高さから、世界中でクリエイターや一般ユーザーに広く利用されています。
Stable Diffusionの大きな特徴は、オープンソースで提供されており、誰でも無料で使用できることです。商用利用も特定の条件下で可能であり、さまざまなクリエイティブプロジェクトに活用されています。また、モデルをカスタマイズして特定のスタイルや対象に特化させられるので、自分好みの画像生成モデルを使用できるのも人気を呼んでいる理由です。
他のAI画像生成サービス(MidjourneyやDALL-E)と比較すると、Stable Diffusionには以下のような特徴があります。
Stable Diffusionを類似画像生成AIと比較

Stable Diffusionを他の画像生成AIサービスと比較すると、以下の特徴が見えてきます。
- オープンソース:ソースコードが公開されており、誰でも改良や拡張が可能
- ローカル環境での実行:自分のPC上で動作させることが可能
- カスタマイズ性:モデルの変更や拡張機能の追加など、自由度が高い
- コミュニティの活発さ:世界中の開発者やユーザーによる継続的な改良がされている
このようにStable Diffusionはただの画像生成AIではなく、一度自分のPC環境に落とし込んでしまえば、自由にカスタマイズして使用できる、もっとも拡張性の高い画像生成モデルと言えます。
Stable Diffusionの利用方法

Stable Diffusionを使って画像を生成するには、2種類の方法が存在します。
- ブラウザ上で利用する
- ローカル環境で利用する
ブラウザ上で利用する方法は、Stable Diffusionがどんなものか試しに使ってみる場合におすすめです。ただし期待通りの画像が生成される保証はありません。誰でもすぐに利用できる点がメリットですが、自分が生成した画像が他の人に見られる心配もあるので、長く使用する場合には向きません。
一方で、Stable Diffusionをローカル環境(自身のPC)で構築してしまえば、思い通りの画像を生成しやすくなり、プライバシーも守られます。AI初心者の方にとっては、構築に少々時間がかかってしまうこともありますが、画像生成の自由度がかなり広がるのでメリットのほうが大きいと言えます。
Stable Diffusionをローカル環境で構築するメリット/デメリット
ローカル環境でStable Diffusionを使用することには、オンラインサービスと比較してさまざまなメリットとデメリットがあります。あなたの目的や環境に合わせて検討してみましょう。
Stable Diffusionをローカル環境で構築するメリット

Stable Diffusionをローカル環境で構築すると、さまざまなメリットがあるのは事実です。以下で詳しく見ていきましょう。
- 無料での無制限利用:Stable Diffusionは基本的に無料で利用できます。オンラインサービスのような月額料金や生成枚数の制限がないため、納得いくまで何度でも生成が可能です。
- プライバシーの保護:生成した画像やプロンプト(指示文)が外部サーバーに送信されないため、プライバシーを守りながら利用できます。特に企業の機密情報や個人的なプロジェクトに活用する場合に安心です。
- 高度なカスタマイズ:さまざまなモデルやLoRA(学習済みの小規模アダプター)、拡張機能を自由に追加・変更できます。これにより、あなた好みのスタイルや特定の対象に特化した画像生成が可能になりました。
- オフライン利用:一度環境を構築すれば、インターネット接続がなくても使用できます。外出先や通信環境の不安定な場所でも利用可能です。
- 処理速度の向上:高性能なGPUを搭載したPCであれば、オンラインサービスよりも高速に画像生成ができることも。特に混雑時や複数枚の一括生成時に差が出やすいです。
- 最新機能を素早く試せる:コミュニティによって開発された新機能やモデルをいち早く導入できます。オンラインサービスでは利用できない最先端の機能も使えます。
- 学習の自由度:自分で用意したデータセットで学習させることにより、オリジナルのモデルを作成することも可能です。
Stable Diffusionのローカル環境構築は、無料かつ無制限で利用できる点とプライバシー保護、高度なカスタマイズ性など多くのメリットがあります。高性能なPCがあれば、自分だけのAI画像生成環境を作り、より自由なクリエイティブな活動を楽しめるでしょう。画像生成の幅が格段にアップしますね。
Stable Diffusionをローカル環境で使用するデメリット

Stable Diffusionをローカル環境で構築するデメリットについても確認しておきましょう。
- 環境構築の複雑さ:Python、CUDA、gitなどのインストールや設定が必要で、初心者にはハードルが高い場合があります。ただし近年では、導入を簡単にするためのツールも登場しています。
- PCスペックの要求:特にGPUの性能(VRAM容量)が重要で、高性能なグラフィックボードが必要になります。使用するモデルや生成する画像サイズによって必要なスペックは変わります。
- 初期投資:高性能なPCを新たに購入する必要がある場合、初期コストが高くなる可能性があります。ただし長期的に見れば、無料サービスなので元が取れる場合が多いです。
- トラブルシューティングの手間:環境構築や使用中に問題が発生した場合、自分で解決する必要があります。エラーメッセージを理解したり、対処法を調べたりする手間がかかります。
- ストレージ容量の圧迫:モデルファイルや生成した画像データは容量が大きく、PCのストレージを圧迫する場合があります。一般的なモデルでも数GB、複数のモデルを導入すると数十GB以上になることも珍しくありません。
- アップデート管理:ソフトウェアや関連ライブラリのアップデートを自分で行う必要があります。互換性の問題が発生することもあるため、注意が必要です。
これらのメリット・デメリットを踏まえ、以下で自身の状況に合ったStable Diffusionをローカル環境で構築する環境をチェックしていきましょう。
Stable Diffusionをローカル環境で構築する環境をチェック
Stable Diffusionを快適に動作させるためには、ある程度のスペックを持ったPCが必要になります。以下で、必要なハードウェアとソフトウェアの要件を確認しましょう。
必要なPCスペックと推奨環境
Stable Diffusionは計算量の多いAIモデルであるため、特にGPU(グラフィックボード)の性能が重要です。
GPU(グラフィックボード)
Stable Diffusionの処理速度と生成できる画像のサイズを左右する最も重要な要素です。
Stable Diffusionを使用するには、CUDA技術が利用できるNVIDIA製GPUが最も相性が良いとされています。AMD製GPUでも動作は可能ですが、設定が複雑になったり、パフォーマンスが十分に発揮できない場合があります。
- 最低限:6GB以上(基本的な使用のみ、512×512ピクセル程度の画像生成)
- 推奨:8GB以上(標準的な使用、標準モデル使用時)
- より快適にするなら:12GB以上(高解像度画像の生成や拡張機能の利用に適しています)
- 高性能を追求するなら: 16GB以上(複数モデルの同時使用や最大解像度の画像生成、最新の大規模モデルにも対応)
実際は、GTX 1660 Super(6GB)でも512×512ピクセルの画像なら生成可能ですが、RTX 3060(12GB)以上あれば、より快適に利用できます。最新のStable Diffusion XLのようなモデルを使用する場合は、RTX 3090(24GB)や4090(24GB)のような高性能GPUが必要になることもあります。
<用語解説>
GTX 1660 Super、RTX 3060など→PC画面に映像を映し出すための重要な部品で、グラフィックボードと呼ばれる物の種類。さまざまなグレードがある。
CPU(中央処理装置)
GPUと比較すると、さほどこだわる必要はありませんが、全体的な動作に影響します。
- 推奨: Intel Core i5以上、またはAMD Ryzen 5以上の比較的新しいモデル
- より快適にするなら: Intel Core i7/i9、AMD Ryzen 7/9の最新モデル
メモリ(RAM)
システム全体の動作に関わるメモリも十分な容量が必要です。
- 最低限: 8GB(基本的な使用のみ)
- 推奨:16GB
- より快適にするなら: 32GB以上(複数の拡張機能や大規模モデルを使用する場合)
ストレージ(SSD/HDD)
Stable Diffusionのモデルや生成された画像を保存するために十分な容量が必要です。
- 推奨:512GB以上のSSD(高速なSSDの方が読み込みや保存が快適)
- 容量目安
- 基本的なプログラム:約10GB
- モデル1つあたり:2GB~7GB
- 生成画像:使用量に応じて増加
ノートPCと比較してデスクトップPCの方が同価格帯でより高性能なGPUを搭載できるため、本格的に使いたい場合はデスクトップPCがおすすめです。ただし最近の高性能ノートPCでも十分に動作するモデルもあります。
Windowsのバージョンを確認する方法
Stable Diffusionをローカル環境で構築する前に、自身のPCのスペックや環境を確認しましょう。推奨するバージョンは、Windows10以上・実装RAM16GBです。確認手順は以下のとおりです。
- 画面左下の「スタート」ボタン(Windowsロゴ)をクリックします。

- 「設定」(歯車アイコン)をクリックします。
- 「システム」を選択します。
- 左側のメニューで下にスクロールし、「バージョン情報」をクリックします。

- 「Windows の仕様」の項目にWindowsのバージョン(Windows 10やWindows 11など)や実装RAMが表示されます。

PCスペックを確認する方法
PCのスペックも確認しておきましょう。
- キーボードの「Windowsキー」+「R」を同時に押します。
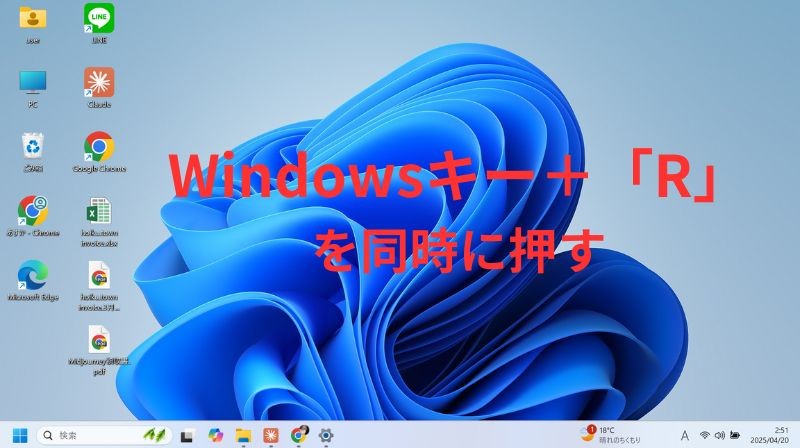
- 「ファイル名を指定して実行」ダイアログに「dxdiag」と入力します。
- 「OK」をクリックします。
- 「DirectX診断ツール」ウィンドウが開きます。
- 「システム」タブでCPUとメモリの情報を確認できます。
- 「ディスプレイ」タブでグラフィックカード(GPU)の情報を確認できます。

これらの方法で、お使いのPCの主要なスペックを簡単に確認することができます。ゲームやStable Diffusionなどの高負荷アプリケーションを実行する前に、必要なスペックを満たしているか確認するのに役立ちます。
対応OS

Stable Diffusionは、以下の主要OSで動作可能です。
- Windows:Windows 10/11(64bit)が最も一般的で、サポートも充実しています。
- Linux:Ubuntu(ウブントゥ)、Debian(デビアン)、Arch Linux(アーチリナックス)などの主要ディストリビューション
- macOS:M1/M2チップ搭載のMacでは専用の最適化が行われており、比較的動作が良好です。ただし、Intel Macでは動作が不安定な場合があります
<用語解説>
ディストリビューション→複数のソフトウェアをまとめて配布、利用できるようにしたパッケージのこと。
特に初心者の方は、Windows環境での構築が最もトラブルが少なく、情報も豊富なためおすすめです。
インストールに必要なソフトウェア一覧

Stable Diffusionをローカル環境で動作させるために、以下のソフトウェアが必要です。
- Python(パイソン):プログラミング言語で、Stable Diffusionの基盤と言えます。
- 推奨バージョン:Python 3.8~3.10(バージョンによって動作が異なる場合があり)
- Git(ギット): コードリポジトリの管理ツールで、Stable DiffusionのWebUIなどをダウンロードするために必要です。
- CUDA Toolkit(NVIDIA製 GPUの場合):GPUを活用するためのフレームワークです。
- GPUドライバーのバージョンと互換性のあるものを選ぶ必要があります。
- Stable Diffusion WebUI:Stable Diffusionを簡単に操作するためのインターフェースです。
- AUTOMATIC1111を利用する際には「Stable-Diffusion-WebUI」が最も適しています
- PyTorch(パイトーチ): 機械学習ライブラリで、Stable Diffusionのモデルを動作させるために必要です。
これらのソフトウェアは、後述するインストール手順で自動的にダウンロード・設定される場合もあります。
StaleDiffusionモデルをローカル環境で構築する方法
ここからは、実際にStable Diffusionをローカル環境に構築する手順を説明します。初心者の方でも分かりやすいよう、Windows環境を前提に説明します。
各ソフトウェアのインストール方法

Pythonのインストール
- Python公式サイトにアクセスします。
- 「Download Python 3.x.x」ボタンをクリックして最新の安定版をダウンロードします。
- ダウンロードしたインストーラーを実行します。
- 【重要】インストール画面で「Add Python 3.x to PATH」にチェックを入れてください。
- 「Install Now」をクリックし、インストールを開始します。
- インストール完了後、コマンドプロンプトを開いて「python –version」 と入力し、バージョン情報が表示されることを確認します。
Gitのインストール
- Git公式サイトにアクセスします。
- インストーラーをダウンロードし、実行します。
- 基本的にはデフォルト設定のまま「Next」をクリックして進めてください。
- インストール完了後、コマンドプロンプトで 「git –version」 と入力し、バージョン情報が表示されることを確認します。
Stable Diffusion WebUI (AUTOMATIC1111)の導入手順

Stable Diffusion WebUIは、ブラウザ上でStable Diffusionを簡単に操作できるインターフェースで、最も普及しているのがAUTOMATIC1111と呼ばれるバージョンです。GUI(グラフィカルインターフェース)で比較的簡単にしかも無料で利用できる点が人気を呼んでいます。
- インストール先フォルダの作成
- エクスプローラーで、Stable Diffusion WebUIをインストールしたい場所に新しいフォルダを作成します。(例:Cドライブ→stable-diffusion-webuiと名前を付ける)
- コマンドプロンプトを開く
- 作成したフォルダ内で右クリックし、「ターミナルで開く」または「コマンドプロンプトをここで開く」を選択します。
- リポジトリのクローン
- 以下のコマンドを入力してEnterキーを押します。
- 「 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git」
- 必要なファイルの自動ダウンロード
- クローン完了後、作成された stable-diffusion-webui フォルダに移動します。
- 以下のコマンドを実行して、必要なファイルをダウンロードします。
「webui-user.bat」 - 初回実行時は、Python環境の構築やライブラリのインストールなどが自動的に行われるため、時間がかかります。(通常10~30分程度)
- WebUIの起動
- インストールが完了すると、ブラウザが自動的に開き、Stable Diffusion WebUIの画面が表示されます。
- 通常、「http://127.0.0.1:7860」というアドレスで実行可能です。
- 初回起動時には、基本的なモデルがインストールされていない場合があります。
- モデルは「Civitai」などのサイトからダウンロードし、「models/Stable-diffusion」フォルダに配置します。
- WebUIの「Settings」タブ→「Reload UI」ボタンをクリックすると、モデルが読み込まれます。
以下の記事では、実際に操作している画像も交えて解説していますので、ぜひ参考にしてください。

よくあるエラーと解決策

Stable Diffusionのローカル環境構築では、いくつかエラーが発生することがあります。ここでは、主なエラーとその解決策を紹介します。
Pythonインストール時のエラー
エラー:「’python’ は、内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチ ファイルとして認識されていません。」
- Pythonをアンインストールし、再インストール時に「Add Python 3.x to PATH」にチェックを入れる
- または、システム環境変数のPathにPythonのインストールパスを手動で追加する
WebUIインストール時のエラー
エラー:git cloneコマンドが失敗する
- インターネット接続を確認する
- プロキシ設定を確認する
- GitHubへのアクセスがブロックされていないか確認する
エラー: webui-user.batの実行時にPythonライブラリ関連のエラーが発生する
- コマンドプロンプトを管理者権限で実行してみる
- 「pip install -r requirements.txt –upgrade」コマンドを実行して必要なライブラリを再インストールする
- Pythonのバージョンが推奨範囲内(3.8~3.10)であることを確認する
エラー: CUDA関連のエラーが発生する
- NVIDIAドライバーが最新であることを確認する
- webui-user.batファイルを編集し、「set COMMANDLINE_ARGS=–skip-torch-cuda-test」という行を追加する
- PyTorchを再インストールする:「pip uninstall torch」を実行後、「pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118」(CUDAバージョンに応じて変更)を実行
困った際はエラーメッセージをよく読み、分からない場合はGitHug公式のトラブルシューティングなどで検索すると、同様の問題に遭遇した人の解決策を見つけられることがあります。
Stable Diffusionローカル環境での基本的な使い方
Stable Diffusion WebUIの基本的な操作方法を説明します。ここで紹介する内容を習得すれば、AIによる画像生成の第一歩が踏み出せます。
WebUIの基本的な操作画面を解説

Stable Diffusion WebUIの画面は、主に以下のようなセクションに分かれています。

①上部メニュー
- txt2img:テキストから画像を生成する機能(最も基本的な機能)
- img2img: 既存の画像を元に新しい画像を生成する機能
- Extras: 画像のアップスケール(拡大)や顔の修正などの機能
- PNG Info: 生成した画像から設定情報を抽出する機能
- Settings:WebUIの設定を変更する画面
- Extensions: 拡張機能の管理画面
②左側パネル(txt2imgタブの場合)
- Prompt:生成したい画像の内容を記述する欄
- Negative prompt: 生成したくない要素を指定する欄
- 生成設定
- Sampling method: 画像生成のアルゴリズム
- Sampling steps: 成の精度(ステップ数が多いほど高品質だが時間がかかる)
- Width/Height:生成する画像のサイズ
- Batch count/size: 一度に生成する画像の数
- CFG Scale:プロンプトへの忠実度(高いほどプロンプト通りだが不自然になりやすい)
- Seed: 乱数の種(同じシードなら同じような画像が生成される)
③右側パネル
- Generate: 画像生成を開始するボタン
- 生成結果表示エリア:生成された画像が表示される場所
- Send to img2img/extras:生成した画像を他の機能で編集するためのボタン
- モデル選択: 使用するStable Diffusionモデルを選択
- VAE選択: 画像の色彩表現に影響するVAEを選択
- Styles: よく使うプロンプトの組み合わせを保存したもの
- LoRA/Embeddings:追加学習モデルの選択
基本的にプロンプトは英語表記で入力しましょう。日本語だとモデル本来の性能が損なわれてしまいます。英語が苦手な場合は、翻訳サービス(文章生成AIなど)を活用すれば日本語を瞬時に英語に変換できるのでとても便利です。
テキストから画像を生成する方法

Stable Diffusionの基本的な使い方である「テキストから画像を生成する方法」を説明します。
- WebUIの上部メニューで「txt2img」タブを選択します。
- 「Prompt」欄に、生成したい画像の内容を英語で入力します。
- 例:a beautiful landscape with mountains, lake, sunset, photorealistic, highly detailed
- 「Negative prompt」欄に、避けたい要素を入力します。
- 例:blurry, low quality, deformed, ugly, bad anatomy
- 基本的な設定を調整します。
- Sampling method: DDIMやEuler aなどがバランスが良いです。
- Sampling steps: 20~30程度が一般的(高いほど精密だが時間がかかる)
- Width/Height:512×512や768×768など(GPUのVRAMに依存)
- CFG Scale:7~9程度が一般的(高すぎると不自然になる)
- 「Generate」ボタンをクリックして画像生成を開始します。
- 生成された画像が中央パネルに表示されます。気に入った画像は右クリックメニューから保存できます。
- 同じような画像を再生成したい場合は、生成された画像の下に表示される「Seed」の値をコピーし、左パネルの「Seed」欄に入力して再度生成します。
基本的なプロンプトの書き方とコツ

Stable Diffusionでより良い画像を生成するためには、適切なプロンプト(指示文)を書くことが重要です。以下にプロンプト作成のコツを紹介します。
- 悪い例:beautiful woman
- 良い例: portrait of a young woman with blue eyes, long blonde hair, smooth skin, gentle smile, natural lighting(青い目、長い金髪、なめらかな肌、優しい笑顔、自然な照明の若い女性のポートレート)
このプロンプトを使うと、記述された特徴を持つ女性の肖像画が生成されます。詳細な特徴を指定することで、AIがより具体的なイメージを生成しやすくなります。
- 色彩:vibrant, colorful, red, pastel colors(鮮やかな、カラフルな、赤い、パステルカラーの)
明るく活気のある色合いや特定の色(この場合は赤)、柔らかいパステルカラーを画像に取り入れたい場合に効果的です。
- 質感:smooth, rough, metallic, glossy(なめらかな、粗い、金属的な、艶やかな)
対象物の手触りや見た目の質感を細かく指定することで、より具体的で魅力的な画像が生成されやすくなります。
- 光源:sunlight, moonlight, studio lighting, dramatic lighting(日光、月光、スタジオライティング、ドラマチックな照明)
自然光(日光や月光)や人工的な照明(スタジオライティングや劇的な照明効果)によって、生成される画像の印象は大きく変わります。
- 雰囲気:peaceful, mysterious, fantasy, sci-fi(平和な、神秘的な、ファンタジー、SF【サイエンス・フィクション】)
穏やかな雰囲気や謎めいた空気感、ファンタジー世界やSF的な未来感など、画像の雰囲気を大きく左右する重要なキーワードとなります。
- oil painting, watercolor, sketch, anime style, 3D render, photorealistic(油絵、水彩画、スケッチ、アニメスタイル、3Dレンダリング、写真のようにリアルな)
古典的な絵画技法(油絵や水彩画)から、現代的な表現(アニメスタイルや3DCG)、写真のようなリアリズムまで、幅広い表現方法を指定できます。
- close-up, wide shot, from above, profile view, front view(クローズアップ、ワイドショット、上からの視点、横顔の視点、正面の視点)
被写体との距離感(クローズアップや広角)や、撮影アングル(上からの俯瞰や横顔、正面からの視点)によって、生成される画像の印象は大きく変わります。
- highly detailed, sharp focus, 8k resolution, professional photography, masterpiece(非常に詳細な、鮮明な焦点、8K解像度、プロフェッショナルな写真、傑作)
細部まで精密に描写された高品質な画像を生成したい場合に効果的なキーワードです。特に写真のようなリアルな画像を生成する際に役立ちます。
- 重視したい単語に括弧をつけると重要度が増す
例: a landscape with (mountains:1.2) and (lake:1.5)
((山:1.2)と(湖:1.5)のある風景)
この例では「山」の重要度を1.2倍に、「湖」の重要度を1.5倍に高めています。数値が大きいほどその要素がより強調されて画像に反映されます。
- 複数の括弧をつけるとさらに重要度が増す
例: a landscape with ((mountains)) and (((lake)))
((山))と(((湖)))のある風景
「山」に二重括弧、「湖」に三重括弧を使っているため、湖が山よりもさらに強調された風景が生成されます。
プロンプトのコツをいくつか紹介しましたが、必ず上手くいくとは限りません。思い通りの画像が生成されるまでは、さまざまな工夫をしながら試行錯誤することが大切です。
ネガティブプロンプトの重要性と書き方

ネガティブプロンプトは、生成したくない要素を指定する機能です。適切に設定することで、画像の品質を大幅に向上させられます。
- 一般的な品質改善用ネガティブプロンプト
例) low quality, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, blurry, deformed, distorted, disfigured, poorly drawn face, poorly drawn hands, mutation, mutated, extra limbs, extra arms, extra legs, fused fingers, too many fingers, malformed limbs, error, text, watermark, signature
(低品質、不自然な体の構造、おかしい手、指の欠損、余分な指、指の数が少ない、切れている画像、最低品質、低品質、普通の品質、ぼやけている、変形している、歪んでいる、形が崩れている、下手に描かれた顔、下手に描かれた手、突然変異、変異している、余分な手足、余分な腕、余分な足、融合した指、指が多すぎる、形が悪い手足、エラー、テキスト、ウォーターマーク、署名)
- 特定の要素を除外する:特定のオブジェクトや特徴を排除したい場合、それらを明示的に記述します。
- 例) 人物の数を制限:multiple people, group(複数の人物、グループ)
- 例) 特定の髪色を避ける:red hair, blonde hair(赤髪、金髪)
- 特定のスタイルを避ける:生成結果のスタイルを制御するために、避けたいスタイルを指定します。
- 例) cartoonish, anime style, 3d rende(漫画風、アニメスタイル、3Dレンダリング)
- 過剰な演出を避ける:モデルが過剰に装飾的な要素を追加する傾向がある場合に役立ちます。
- 例) oversaturated, high contrast, dramatic lighting(彩度が高すぎる、コントラストが強い、ドラマチックな照明)
ネガティブプロンプトは長くなる傾向がありますが、一度良い組み合わせが見つかれば保存しておき、繰り返し使用するのが効率的です。WebUIの「Styles」機能を使えば、よく使うプロンプトとネガティブプロンプトの組み合わせを保存できます。
より高品質な画像を生成するには
Stable Diffusionの基本的な使い方をマスターしたら、次はより高品質な画像を生成するための拡張的な手法を学びましょう。まずは追加モデルの活用方法について説明します。
LoRA(学習済みモデル)の活用

LoRA(Low-Rank Adaptation)は、Stable Diffusionの基本モデルに特定のスタイルや特徴を追加するための小規模な学習済みモデルです。ベースモデルを変更することなく、特定の要素だけを強化できる便利な機能です。
LoRAの特徴
- 小さいファイルサイズ: 一般的に数MB~数百MB程度と、ベースモデルと比較して非常に小さいサイズです。
- 組み合わせ可能:複数のLoRAを同時に適用できるため、さまざまな特徴を組み合わせられます。
- 特化型:特定のキャラクター、スタイル、オブジェクトなどに特化しています。
LoRAの入手方法
- Civitai:CIVITAI AI – 最も人気のあるモデル共有サイトで、多数のLoRAが公開されています。
- Hugging Face:Hugging Face – 研究者や開発者が公開するモデルが多いサイトです。
LoRAの使用方法①
- ダウンロードしたLoRAファイル(.safetensorsまたは.ptファイル)を「models/Lora」フォルダに配置します。
- WebUIを再起動するか、「Settings」タブの「Reload UI」ボタンをクリックします。
- LoRAを適用する方法は2つあります。
- 方法1:プロンプトに直接記述する
<lora:ファイル名:強度> 形式で指定します。
例:beautiful landscape <lora:more_details:0.7> - 方法2: WebUIの右側パネルのLoRAを選択します。
- 方法1:プロンプトに直接記述する
LoRAの使用方法②
- WebUIの右側パネルのLoRA選択エリアから選択する
- 使用したいLoRAをドロップダウンメニューから選択し、強度スライダーを調整します。
LoRAの強度は通常0.0〜1.0の範囲で調整でき、値が大きいほどLoRAの効果が強く表れます。最適な強度は各LoRAによって異なるため、いくつかの値を試してみるとよいでしょう。
VAE(Variational Autoencoder)の設定

VAEは、生成画像の色彩や細部の表現に大きく影響を与える重要な構成要素です。適切なVAEを選ぶことで、同じプロンプトでもより美しい画像が生成されることがあります。
VAEの役割
- 潜在空間からピクセル画像への変換を担当
- 色彩のバランス、彩度、コントラストに影響
- 細部の表現、特に肌の質感や髪の毛などの繊細な部分に影響
おすすめのVAE
- vae-ft-mse-840000-ema-pruned:汎用性が高く、多くのモデルで良好に動作します。
- orangemix.vae.pt:アニメ系モデルとの相性が良いVAEです。
- kl-f8-anime2: 鮮やかな色彩を表現するのに優れています。
VAEの使用方法
- ダウンロードしたVAEファイル(.safetensorsまたは.ptファイル)を「models/VAE」フォルダに配置します。
- WebUIを再起動するか、「Settings」タブの「Reload UI」ボタンをクリックします。
- 右側パネルの「VAE」ドロップダウンメニューから使用したいVAEを選択します。
- 「None」を選択すると、現在のモデルに内蔵されているデフォルトのVAEが使用されます。
アップスケーラーの設定

生成した画像をより高解像度にアップスケール(拡大)する機能も、高品質な画像を得るために重要です。Stable Diffusion WebUIには、複数のアップスケーリングアルゴリズムが用意されています。
アップスケーリングの方法
- Extrasタブを使用
- 生成した画像を「Send to extras」ボタンで送るか、Extrasタブで画像をアップロード
- 使用するアップスケーラーと拡大率を選択
- 「Generate」ボタンをクリック
- img2imgのアップスケーリングモード
- img2imgタブを開き、「Resize」セクションの「Upscaling」を選択
- 適用したい拡大率とアップスケーラーを選択
- デノイジング強度を低めに設定(0.2~0.4程度)
- 「Generate」ボタンをクリック
おすすめのアップスケーラー
- R-ESRGAN 4x+:写真やリアルなスタイルの画像に適しています。
- SwinIR 4x:精細な部分の保持に優れています。
- LDSR:時間はかかりますが、高品質なアップスケールが可能です。
アップスケーリングの際は、品質と処理時間のバランスを考慮しながら最適なアルゴリズムを選択するとよいでしょう。
拡張機能の活用

Stable Diffusion WebUIの大きな魅力の一つは、拡張機能(Extensions)を追加できることです。これにより、基本機能だけでは難しい高度な画像生成や編集が可能になります。
主要な拡張機能
- ControlNet
- 構図、ポーズ、線画などを指定して画像を生成できる強力な拡張機能
- スケッチから詳細な画像を生成したり、特定のポーズを維持したまま人物画像が生成可能
- 導入方法:WebUIの「Extensions」タブで「Install from URL」に 「https://github.com/Mikubill/sd-webui-controlnet」を入力してインストール
- Additional Networks(追加ネットワーク)
- LoRAやLyCORISなどの追加モデルを簡単に管理・適用できる拡張機能
- プレビュー表示や複数モデルの同時適用が簡単に
- 導入方法:WebUIの「Extensions」タブで「Install from URL」に 「https://github.com/kohya-ss/sd-webui-additional-networks」を入力
- Image Browser(画像ブラウザ)
- 生成した画像を簡単に閲覧・管理できる拡張機能
- 使用したモデルやプロンプトでの検索も可能
- 導入方法: WebUIの「Extensions」タブで「Available」から「Image Browser」を検索してインストール
- ADetailer(自動詳細化)
- 生成された人物画像の顔や手などを自動的に検出し、高品質に修正する拡張機能
- 特に手の描写が苦手なモデルでの画像生成に有効
- 導入方法: WebUIの「Extensions」タブで「Available」から「ADetailer」を検索してインストール
これらの拡張機能を活用することで、ローカル環境でのStable Diffusionの可能性が大きく広がります。さらに拡張機能は常に新しいものが開発されているため、WebUIの「Extensions」タブの「Available」セクションをチェックして、最新の機能を探してみるとよいでしょう。
Stable Diffusionをローカル環境で使用する際のよくある質問
ここでは、Stable Diffusionのローカル環境利用に関するよくある質問と回答をまとめました。構築や使用に際しての疑問点を解消するために、ぜひ役立ててください。
Stable Diffusionのローカル環境での料金は?

Stable Diffusionのソフトウェア自体は無料で利用できます。これはオープンソースプロジェクトであるため、使用に際してライセンス料などは発生しません。ただし以下の費用が考えられます。
- ハードウェア費用:高性能なGPUを搭載したPCの購入・アップグレード費用がかかります。
- 電気代:画像生成中はGPUが高負荷で動作するため、通常のPC使用時より電力消費が増加します。
- ストレージ費用:多数のモデルやLoRAを保存する場合、追加のストレージが必要になる場合があります。
長期的に見ると、オンラインサービスの月額料金と比較して経済的な場合が多いです。特に頻繁に使用する場合や、複数の人で共有して使う場合はコスト効率が高いためおすすめです。
Stable Diffusionは商用利用できる?

Stable Diffusionのモデルは特定条件下で商用利用が可能です。使用するモデルのライセンスによっては、商用利用できない場合もあるので、注意が必要です。
- 基本モデル:公式のStable Diffusionモデル(v1.x、v2.x)は、CreativeML Open RAIL-Mライセンスの下で提供されており、一定の制限内で商用利用が可能です。ただし、有害なコンテンツ生成などの悪用は禁止されています。
- コミュニティモデル:Civitaiなどで公開されている各モデルは、モデル作成者が定めたライセンスに従います。商用利用が許可されているモデルもあれば、個人利用のみのモデルもあります。
- 学習データに関する考慮:モデルの学習に使用されたデータの著作権についても考慮する必要があります。
商用利用を検討している場合は、使用するモデルの具体的なライセンス条件を確認することをおすすめします。また生成された画像の著作権に関しては、各国の法律によって解釈が異なる場合があるため、法的なアドバイスを求めましょう。
Stable Diffusionのローカル環境構築に制限はある?

Stable Diffusionのローカル環境構築には、いくつかの制限が存在します。
- PCスペックの制限
- 最も大きな制限はGPUのVRAM容量です。最低でも6GB、推奨は8GB以上のVRAMが必要です。
- CPUだけでも動作はしますが、1枚の画像生成に数十分から数時間かかる場合があり、実用的ではありません。
- OS制限
- Windows、Linux、macOSのいずれかが必要です。
- macOSの場合はApple Silicon(M1/M2/M3チップ)搭載機が推奨されます。
- 技術的なハードル
- コマンドラインの基本操作や、ソフトウェアインストールの経験が役立ちます。
- エラーが発生した場合のトラブルシューティング能力も重要です。
- ストレージ容量
- モデルファイルは1つあたり2〜7GB程度のサイズがあり、複数のモデルを使用する場合は数十GB以上のストレージが必要です。
これらの制限は、より高性能なハードウェアやより多くの知識を得ることで克服できますが、初心者がすぐに快適な環境を構築するのは難しい場合もあります。
Mac環境でもStable Diffusionを使用できる?

MacでもStable Diffusionを実行することは可能ですが、いくつかの注意点があります。
- M1/M2/M3チップ搭載Mac
- Apple SiliconのGPUを活用できるため、比較的高速に動作します。
- 専用の最適化済みWebUIが公開されています。https://github.com/AUTOMATIC1111/stable-diffusion-webui-macOS
- Intel Mac
- 性能が限られるため、画像生成に時間がかかる場合があります。
- 互換性の問題が発生することもあります。
- インストール方法の違い
- MacではいくつかのPython依存関係の扱いがWindowsと異なります。
- インストール時に追加のパッケージが必要になる場合があります。
- パフォーマンスの最適化
- リソースが限られる場合は、小さいサイズの画像生成から始めることをおすすめします。
- 拡張機能の一部は、Mac環境では動作が遅くなったり、互換性の問題が発生したりする場合があります。
Mac環境での具体的なインストール手順や最適化については、GitHub上のmacOS向けStable Diffusion WebUIリポジトリのドキュメントを参照することをおすすめします。
CPU環境でのStable Diffusionの実行は可能?

GPUがない環境でもStable Diffusionを実行することは可能ですが、大きな制限があります。
- 処理速度
- CPUのみの環境では、1枚の画像生成に数十分から数時間かかることがあります。
- 同じ画像をGPU環境では数秒〜数十秒で生成できることと比較すると、大きな差があります。
- 設定の制限
- 小さいサイズの画像(256×256ピクセルなど)や、ステップ数の少ない設定にする必要があります。
- 一部の拡張機能やモデルはCPU環境では動作しない場合があります。
- 専用のオプション
- WebUIを起動する際に 「–use-cpu all」 オプションを追加することで、すべての処理でCPUを使用するよう指定できます。
- 「–precision full –nohalf」オプションを追加すると、CPUでの互換性が向上する場合があります。
CPU環境でのStable Diffusion利用は、テスト目的や簡単な実験に適していますが、実用的な用途では非常に制限があることを理解しておきましょう。本格的に利用する場合は、NVIDIA製GPUを搭載したPC環境を用意することをおすすめします。
最新のStable Diffusionモデルをローカル環境で使用するには?

Stable Diffusionは継続的に進化しており、新しいバージョンやコミュニティによる改良モデルが常にリリースされています。最新モデルを使用するには以下を準備しておきましょう。
- モデルのダウンロード
- Civitai (https://civitai.com/)
- Hugging Face (https://huggingface.co/)
- AUTOMATIC1111 WebUIのモデルダウンローダー機能 ※上記のサイトから最新モデルをダウンロードできます。
- モデルの保存場所
- ダウンロードしたモデルファイル(.safetensorsまたは.ckptファイル)を「models/Stable-diffusion」フォルダに配置します。
- モデルの保存場所を変更したい場合は、WebUIの「Settings」タブで「Stable Diffusion」セクションの「Model directories」を編集します。
- モデルの追加と使用
- WebUIを再起動するか、「Settings」タブの「Reload UI」ボタンをクリックします。
- 右側パネルの「Stable Diffusion checkpoint」ドロップダウンメニューから新しいモデルを選択します。
- 最新機能への対応
- 最新のStable Diffusion XLなどの新しいアーキテクチャのモデルを使用する場合は、WebUI自体も最新版に更新する必要があることも。
- WebUIのアップデートは、stable-diffusion-webuiフォルダで「git pull」コマンドを実行するか、WebUIの「Update」ボタンをクリックします。
最新モデルを活用することで、Stable Diffusionの可能性をさらに広げられます。特に、Stable Diffusion XL(SDXL)モデルは従来のモデルよりも高品質な画像生成が可能ですが、より多くのVRAM(推奨12GB以上)が必要になる点に注意しましょう。







