
ここ近年で画像生成AI技術は、飛躍的な進化を遂げました。なかでもStable Diffusionは圧倒的な品質の高さから世界中で脚光を浴びています。現在では「Stable Diffusion Web UI」と呼ばれるWebブラウザ上で誰でも簡単に操作できるようにするツールまで登場するほどです。
そんな中、「Stable Diffusion Web UIって何?」「使い方が難しそう」と感じている方も少なからずいることでしょう。
本記事では、Stable Diffusion Web UIの基本概念から他の画像生成AIとの違い、具体的な使い方まで初心者にもわかりやすく解説します。また、インストール方法から実践的なコツまで網羅しているので、読み終わる頃には自分だけの素晴らしいAI画像を生成できるようになっていますよ。
Stable Diffusion Web UIとは
Stable Diffusion Web UIは、Stable Diffusionという画像生成AIモデルをブラウザ上で簡単に利用するためのグラフィカルインターフェース(GUI)※です。コードを書かなくても、直感的な操作でAI画像生成を行えるようになっています。中でも「AUTOMATIC1111」と呼ばれるバージョンが最も人気で、さまざまな機能や拡張性を備えています。
<用語解説>
※グラフィカルインターフェース(GUI)とは…文字入力ではなく、アイコンやボタンなどのグラフィック要素を使って行う方式のこと。
Stable Diffusionと Stable Diffusion Web UIの違い

Stable Diffusion単体ではコマンドライン※での操作が必要ですが、Stable Diffusion Web UIを使えば、ブラウザ上で直感的にAI画像生成が可能です。
そもそもStable Diffusionは、テキストや画像から新しい画像を生成できる拡散モデル(Diffusion Model)がベースの画像生成AIです。2022年に公開されて以来、そのオープンソース※の特性と高品質な生成結果により、多くのクリエイターから支持を集めてきました。
「Stable Diffusion」というのはモデル自体を指し、これを動かすには何らかのインターフェースが必要です。Stable Diffusion Web UIは、そのStable Diffusionを操作するためのグラフィカルなインターフェースです。つまり、Stable Diffusionが「エンジン」だとすれば、Stable Diffusion Web UIは複数の情報を一覧で確認できる「ダッシュボード」のような存在と言えるでしょう。
Stable Diffusion Web UIを使用すれば、特に技術的知識がない初心者でも、Web UIがあることで複雑な設定やコーディングなしにStable Diffusionの機能を活用できるのです。
<用語解説>
※コマンドラインとは…コンピュータに文字で命令を入力して操作する方式のこと。
※オープンソースとは…ソフトウェアの設計図(ソースコード)が一般に公開され、誰でも自由に見たり、修正したり、再配布したりできるソフトウェアのこと。言わば、「みんなで育てていくソフトウェア」のようなイメージ。
Stable Diffusionついては、次の記事で詳しく解説しています。実際にどんな画像が生成できるのか気になる人は、ぜひチェックしてみてください。

Stable Diffusion Web UIの8つの主要機能
Stable Diffusion Web UIには数多くの機能が搭載されていますが、ここでは特に重要な8つの機能を詳しく解説します。
txt2img(テキストプロンプトから画像生成)

txt2imgは、テキストプロンプト(指示文)から画像を生成する最も基本的な機能です。例えば「夕日に照らされた富士山」というプロンプトを入力すれば、AIがそのイメージに近い画像を生成します。細かいスタイルや構図も指定できるため、「写実的なスタイルの、夕日に照らされた富士山を湖に映る構図で」といった複雑な指示も可能です。
ちなみに、生成画像の品質やスタイルを調整するパラメータ※も豊富で、以下のような設定が可能です。
| <豊富なパラメータ> Sampling steps(サンプリングステップ):値が高いほど詳細な画像になりますが、生成時間も長くなる CFG Scale(ガイダンススケール):プロンプトへの忠実度を調整 Width/Height(幅/高さ):画像サイズを指定 Seed(シード値):特定の値を設定すると、同じような画像を再現できます。 |
<用語解説>
※パラメータとは…あるシステムや処理において結果に影響を与える設定可能な値のこと
img2img(画像から画像生成)

img2img(テキスト・ツー・イメージ)は、既存の画像をベースに新しい画像を生成する機能です。例えば手描きのラフスケッチをアップロードし、「油絵風の風景」というプロンプトを加えれば、スケッチの構図を保ちながらリアルな油絵風の風景に変換できます。
この機能の特徴的なパラメータは「Denoising strength(ノイズ除去強度)」で、値を低くすると元画像の特徴を多く残し、高くすると大胆な変更が加わります。写真の一部だけ変更したい場合や、ざっくりとしたアイデアを瞬時に具現化させたい場合にとても便利です。
インペインティング(部分的な画像編集)

インペインティングは、画像の特定部分のみを選択して編集する機能です。例えば、風景写真の空の部分だけを選択して「夕焼け空」に変更したり、人物の服の色だけを変えたりといった部分的な編集ができます。
使い方は編集したい部分を選択し、その部分に対してプロンプトで指示するだけ。画像全体を生成し直すよりも、特定の要素だけを変更したい場合に効果的な機能です。
カラースケッチ(詳細なカラー画像の生成)

カラースケッチ機能は、簡単な色付きの下絵やスケッチをベースに、AIが詳細なカラー画像を生成する機能です。例えば、単純な色ブロックで構成された人物の輪郭があれば、それをリアルな人物画像に変換できます。
この機能はイラストレーターやデザイナーにとって特に役立つ機能で、ラフなアイデアを素早く視覚化するのに役立ちます。また、絵の苦手な人でも簡単なスケッチから印象的な画像を作れるというメリットもあるでしょう。
プロンプトマトリックス(一度に複数のバリエーションの画像を生成)

プロンプトマトリックス機能を使うと、一度に複数のバリエーションの画像を生成できます。例えば「{赤い,青い,緑の}ドレスを着た{若い,年配の}女性」というプロンプトを入力すると、「赤いドレスを着た若い女性」「青いドレスを着た若い女性」など、指定した組み合わせの画像を複数枚にわたってまとめて生成します。
さまざまなバリエーションを一度に比較できるため、ユーザーの目標に一番近いものを効率よく見つけられます。特に商品デザインやキャラクターデザインなど、複数の選択肢から比較検討したい場合に役立つ機能です。
アップスケール(画像拡大)

アップスケール機能は、生成された低解像度の画像を高解像度に拡大する機能です。通常の単純拡大と違って、AIが細部を補完しながら拡大するため、画質の劣化を最小限に抑えられます。
Stable Diffusion Web UIには複数のアップスケーラーが内蔵されており、用途に応じて選択可能です。例えば「ESRGAN(イーエスアールガン)」はリアルな写真の拡大に、「SwinIR(スウィンアイアール)」はイラストの拡大に適しています。大きなサイズで印刷したい場合や、細部までこだわりたい場合に便利な機能です。
アテンション(特定要素の強調)

アテンションは、プロンプト内の特定のキーワードの重要度を調整する機能です。例えば「(赤い花:1.5)と青い空」というプロンプトでは、「赤い花」の重要度が1.5倍になり、生成画像では赤い花がより目立つ結果になります。
逆に「(雲:0.7)のある青い空」とすれば、雲の存在感が控えめになります。この機能を使いこなすことで、画像の主題や雰囲気をコントロールしやすくなり、より意図に沿った画像生成が可能です。
モデルの切り替え

Stable Diffusion Web UIでは、さまざまな事前学習済みモデル(チェックポイント)を切り替えて使用できます。例えば「Realistic Vision(リアリスティック・ビジョン)」はリアルな人物写真に、「Counterfeit(カウンターフィット)」はアニメ調のイラストに特化しています。
モデルによって得意とする画風や被写体が異なるため、目的に応じて適切なモデルを選ぶことで、より質の高い画像生成が可能です。公式モデル以外にも、コミュニティによって作成された特化型モデルも多く公開されており、これらを導入することで表現の幅がさらに広がります。
AUTOMATIC1111版とForge版の違い

Stable Diffusion Web UIにはいくつかのバージョンがありますが、最もよく使われているのが「Forge(フォージ)版」と「AUTOMATIC1111(オートマチック イレブン・イレブン)版」です。それぞれに特徴があるので、用途に応じて選択すると良いでしょう。
<AUTOMATIC1111版とForge版の比較表>
| 比較項目 | Forge版 | AUTOMATIC1111版 |
|---|---|---|
| GPUメモリ使用率 | 良い (低スペックPCでも動作しやすい) | 普通 |
| PCのスペック | 低くてもOK | 高い (GPUメモリ使用量が多い) |
| 最適化技術の導入 | 積極的 (最新の技術を取り入れている) | 比較的緩やか |
| インターフェース※ | シンプル (初心者にも扱いやすい) | 多機能 (慣れが必要な場合あり) |
| ワークフローの柔軟性 | 高い (モジュラー設計※) | 普通 |
| 機能の豊富さ | 比較的少ない (シンプルさを重視) | 多い (拡張機能が豊富) |
| 安定性 | 比較的高い (最新技術導入により不安定な場合あり) | 高い (長期で開発されているため確かな実績あり) |
| コミュニティサポート | 比較的少ない (新しいプロジェクトのため) | 多い (情報が豊富で困ったときに助けを受けやすい) |
| 詳細な設定・調整 | 比較的簡単 | 複雑 (上級者向けの細かな設定項目が多い) |
| おすすめな人 | 初心者向け (導入しやすく、動作も快適) | 中級者~上級者向け (設定項目がやや複雑)) |
<用語解説>
※インターフェースとは…Webブラウザ上でモデルを操作するための画面や操作方法のこと。
※モジュラー設計とは…システムや製品を、独立した機能を持つ小さな部品(モジュール)に分割し、それらを組み合わせることで全体を構成する設計手法のこと
初心者や低スペックPCを使用している方は「Forge版」が向いています。一方で、より多くの機能や拡張性を求める方は「AUTOMATIC1111版」がおすすめです。本記事では最も普及しているAUTOMATIC1111版の使い方を中心に解説していきます。
Stable Diffusion Web UIの料金プランと注意点

Stable Diffusion Web UIの最大の魅力の一つは、完全無料で利用できることです。オープンソースプロジェクトとして公開されているため使用回数の制限もなく、自分のPC環境にインストールして無制限に使用できます。
ただし、使用するには以下の点に注意が必要です。
| <Stable Diffusion Web UIを使用する際の注意点> 自分のPCの特にGPUやCPUを使用するため、電気代などのランニングコストはかかる 高品質な画像生成には比較的高性能なGPUが必要 学習済みモデルの中には有料のものもある(ただし、無料モデルも多数あり) |
<用語解説>
※GPUとは…「Graphics Processing Unit(グラフィックス プロセッシング ユニット)」の略で、主にパソコンで画像や映像を表示するための計算処理を行う部品
※CPUとは…「Central Processing Unit(中央処理装置)」の略で、コンピュータの頭脳とも言える最も重要な部品のこと
クラウドサービスのように月額料金が発生しないため、長期的に使用する場合はコスト面で大きなメリットがあります。特にクリエイターやデザイナーなど、頻繁に画像生成を行う方にとっては経済的な面で嬉しいツールの1つです。
Stable Diffusion Web UIのメリットとデメリット
Stable Diffusion Web UIを使う前に、そのメリットとデメリットをしっかり理解しておきましょう。
Stable Diffusion Web UI のメリット

Stable Diffusion Web UIには、特に自由度の高さとコスト面での強みが際立っており、クリエイターやデザイナーから高い支持を得ています。以下に主なメリットを紹介します。
- 無料で利用可能
- 商用利用も含めて基本的に無料で使用できる
- 使用回数や生成枚数に制限がない
- クラウドサービスのような月額料金が発生しない
- 直感的なグラフィカルインターフェース
- コードを書かなくても操作可能
- ブラウザベースで使いやすい
- パラメータ調整がスライダーなどで視覚的に行える
- 拡張機能によるカスタマイズ性
- 豊富な拡張機能でさらに機能を追加できる
- 自分の用途に合わせたワークフローを構築可能
- コミュニティの作成者が作製した特殊モデルを活用できる
- 統合された機能セット
- テキストから画像、画像から画像、インペインティングなどの機能が豊富
- アップスケールなどの画像処理機能も内蔵
- さまざまなニーズに対応する一体型ソリューション
- オフライン利用でセキュアに使用可能
- 生成した画像がクラウドにアップロードされない
- プライバシー保護の観点で安心
- インターネット接続なしでも使用可能(初回設定後)
Stable Diffusionは無料で高品質な画像生成が可能なこと、プライバシーを重視するオフライン利用もできる点が素晴らしいです。特に直感的なインターフェースと豊富な拡張機能により、コーディングスキルがなくても専門的な画像生成ができる点は、クリエイターにとって大きな魅力でしょう。コミュニティが作成した特殊モデルを活用できる点も、創造性をさらに広げられます。
Stable Diffusion Web UI のデメリット

Stable Diffusion Web UIはメリットが多くある反面、少なからずデメリットもあります。以下の点も頭に入れておきましょう。
- ハイスペックなPC環境が必要
- NVIDIA製GPUがほぼ必須(VRAM 6GB以上推奨)
- 処理速度はGPUの性能に依存
- ストレージ容量も20GB以上必要
- 初期設定や操作に専門知識が必要
- インストール手順が一般ユーザーには複雑
- エラー発生時のトラブルシューティングが難しい
- 英語インターフェースが基本(日本語化は可能)
- 利用可能な環境に制約がある
- Mac(特にM1/M2)での動作は制限あり
- ノートPCでは性能・発熱の問題があることも
- Linux環境では追加設定が必要になることも
- セキュリティ上のリスク
- サードパーティ製モデルや拡張機能にはリスクが伴うことも
- モデルのダウンロード元の信頼性確認が必要
- オープンソースのため、セキュリティアップデートの把握が必要
- 法的な問題
- 生成画像の著作権や利用範囲の問題
- 特定のコンテンツ生成に関する法的制限の理解が必要
- 商用利用の場合は特に注意が必要
Stable Diffusion Web UIは強力なツールですが、これらのメリットとデメリットを理解した上で使用することが重要です。特に初心者の方は、最初はシンプルな使い方から始めて、徐々に機能を拡張していくことをおすすめします。
Stable Diffusion Web UIと他画像生成AIとの違い

画像生成AI市場には「Stable Diffusion Web UI」を含め「Midjourney」「DALL-E 3」など、さまざまなサービスが存在します。ここでは主要な画像生成AIとStable Diffusion Web UIを比較してみます。今回比較するサービスは、以下のとおりです。
- Stable Diffusion Web UI
- Midjourney
- DALL-E 3
- Bing Image Creator
| 比較項目 | Stable Diffusion Web UI | Midjourney | DALL-E 3 | Bing Image Creator |
|---|---|---|---|---|
| 料金 | 無料 | 有料($10~/月) | 有料クレジット制 | 一部無料 |
| 使いやすさ | ★★☆☆☆ | ★★★★☆ | ★★★★★ | ★★★★☆ |
| カスタマイズ性 | ★★★★★ | ★★☆☆☆ | ★☆☆☆☆ | ★☆☆☆☆ |
| 生成品質 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★☆☆ |
| 特徴 | 無制限生成高度なカスタマイズ可能ローカル環境依存 | Discord上で動作高品質な芸術的画像生成に強み | OpenAI製シンプルな操作性自然な言語理解 | Bing検索と統合簡単な操作Microsoftアカウントが必要 |
| オフライン使用 | 〇 | × | × | × |
| 必要環境 | 高性能PC(GPU必須) | インターネット接続 | インターネット接続 | インターネット接続 |
| 更新頻度 | 頻繁(コミュニティ主導) | 定期的 | 定期的 | 定期的 |
Stable Diffusion Web UIの最大の特徴は、無料で無制限に使用できること、そしてカスタマイズ性の高さです。しかし初期設定や操作方法の学習コストが他のサービスより高いという特徴があります。
特に以下のような方にはStable Diffusion Web UIがおすすめです。
| <Stable Diffusion Web UIがこんな人におすすめ> コスト重視で画像生成AIを使いたい方 細かいパラメータ調整や拡張機能でカスタマイズしたい方 プライバシーを重視し、ローカル環境で完結させたい方 自分のペースで無制限に画像生成を行いたい方 |
手軽さや簡単な操作性を重視する方には、MidjourneyやDALL-E 3などのクラウドサービスの方が向いていると言えるでしょう。
Stable Diffusion Web UIの始め方
Stable Diffusion Web UIをローカル環境にインストールする方法はいくつかありますが、ここでは初心者でも簡単に導入できる「クラウドサービスを利用する方法」と「Google Colaboratory(Google Colab)を利用する方法」を紹介します。
クラウドサービスを利用する方法(手軽さ重視)

クラウドサービスは、自分のPCにStable Diffusion Web UIをインストールする必要がなく、Webブラウザ上で利用できるため、初心者の方でも比較的簡単に始められます。
クラウドサービスの種類には「RunPod」や「Paperspace」などいくつかありますが、ここでは「RunPod」を一例として取り上げます。
<RunPodを使用したクラウドサービスの始め方>
- RunPodのWebサイトにアクセスし、アカウントを作成する
- 「Explore」から、Stable Diffusion Web UI がプリインストールされたテンプレート「Stable Diffusion WebUI Forge」を選択

- 利用するGPUの種類やスペックを選択(最初は安価なGPUから試すのがおすすめです。)

- インスタンスを選択したら、「オンデマンドで展開」をクリックし、支払い設定をする

- 表示されるURLにアクセスすると、Stable Diffusion Web UI がWebブラウザで開きます。
Google Colaboratory (Google Colab) を利用する方法(コスト重視)

Google Colab は、Googleが提供する無料のクラウドベースのJupyter Notebook※環境です。無料でGPUを利用できるため、Stable Diffusion Web UI を無料で試したい方におすすめです。
<用語解説>
※Jupyter Notebookとは…Webブラウザ上でコードの記述、実行、結果の表示、そしてドキュメント作成を1つの環境で行える双方的なやり取りができる開発環境のこと。
<Google Colabで始める方法>
- Googleアカウントを用意
- 「Stable Diffusion WebUI Colab」から、ノートブックを見つける
- ノートブックを開く(今回はStable Diffusion WebUi – Altryneを使用)
- ノートブックにある「コードセル」を実行していく(最初の再生ボタンを押すと、自動的に最後まで実行可能)

- 生成されたWeb UIのURLをクリックすると、Stable Diffusion Web UIの画面が開く


こちらがStable Diffusion Web UIの画面です。
※もし何らかのエラーによりURLがクリックできなければ、以下の方法を試してみましょう。
- 右クリックでコピーし、検索サイトに貼り付ける
- 右クリックで「Googleレンズ」を利用する
Stable Diffusion Web UIの使い方
Stable Diffusion Web UIのインターフェースは複数のタブで構成されています。ここでは基本的な使い方を紹介します。
txt2imgの使い方

txt2imgとは、テキストによるプロンプトから画像を生成する方法です。
- 上部タブから「txt2img」を選択
- プロンプトの入力
- 上部テキストボックスに生成したい画像の詳細を英語で記述する
- 例:「a beautiful landscape with mountains, lake, sunset, photorealistic, detailed」(美しい山々、湖、夕日のある風景、写真のようにリアルで詳細なもの)
- 下部テキストボックスには避けたい要素を記述する(ネガティブプロンプト)
- 「blurry, low quality, distorted, deformed」(ぼやけた、低品質、歪んだ、変形した)

- 生成設定の調整
- Sampling method:サンプリング方法(初心者には「DPM++ 2M Karras」がおすすめ)
- Sampling steps:ステップ数(20〜30程度が一般的)
- Width/Height:画像サイズ(初めは512×512など小さめに)
- CFG Scale:プロンプトへの忠実度(7〜12が一般的)
- Seed:シード値(-1でランダム生成、特定の値を入れると再現可能)
- 「Generate」ボタンをクリック

Generateをクリックすると、数秒〜数十秒で画像が生成される


こちらが生成された画像です。とてもリアルで情緒あふれる景色が現れました。この鮮やかな配色と奥行きを感じられる描き方は現代ゲームの世界に入り込んでいるかのようです。
画像の下に表示されるボタンから保存や変更も可能で、気に入った画像のSeed値を記録しておくと、同じような画像を再現できます。

img2imgの使い方
img1imgとは、元画像を読み込ませ、その画像を基に新たな画像を生成する方法です。今回は例として、以下のウサギのラフスケッチを使用しましょう。

- 上部タブから「img2img」を選択
- 元となる画像をアップロード
- 「Upload」ボタンから画像を選択
- または画像をドラッグ&ドロップ

- プロンプトの入力
- txt2imgと同様にプロンプトとネガティブプロンプトを入力

- Denoising strength(変化の度合い)の調整
- 0に近いほど元画像に近く、1に近いほど大きく変化します
- ラフスケッチから詳細画像を作る場合は0.7〜0.9程度
- 写真の一部を変更する場合は0.3〜0.5程度

- 「Generate」ボタンをクリック

このほか、「Inpaint」タブでは画像の一部だけを編集したり、「Extras」タブでは画像のアップスケールや顔の修正などが行えます。慣れてきたら、さまざまな機能を試してみましょう。
Stable Diffusion Web UIでの画像生成例
Stable Diffusion Web UIを使って、どのような画像が生成できるのか、いくつかの例を紹介します。
風景画像の生成例
プロンプト:
「beautiful mountain landscape with a lake, snow-capped peaks, reflection in water, sunset colors, photorealistic, detailed vegetation, 8k, masterpiece」
(美しい山の風景、湖があり、雪をかぶった山頂、水面に映る反射、夕日の色彩、写真のようにリアルで、詳細な植生、8K、傑作)
ネガティブプロンプト:
「blurry, low quality, distorted, deformed, ugly, unnatural colors」
(ぼやけた、低品質、歪んだ、変形した、醜い、不自然な色彩)
設定:
- Sampling method:DPM++ 2M Karras
- Sampling steps::30
- CFG Scale::9
- Size: 768×512

このようなプロンプトで、息をのむような美しい風景写真を生成することができます。光の当たり方や反射など、細部まで美しく表現されています。
キャラクターイラストの生成例
プロンプト:
「anime girl, short blue hair, school uniform, cheerful expression, outdoors, cherry blossom, sunshine, detailed, best quality, studio ghibli style」
(アニメの少女、短い青い髪、学校の制服、明るい表情、屋外、桜の花、太陽の光、詳細、最高品質、スタジオジブリ風)
ネガティブプロンプト:
「bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality」
(アニメの少女、短い青い髪、学校の制服、明るい表情、屋外、桜の花、太陽の光、詳細、最高品質、スタジオジブリ風)
設定:
- Model:Anything-V4.5(アニメ特化モデル)
- Sampling method:Euler a
- Sampling steps:28
- CFG Scale:7
- Size:512×768

アニメ特化モデルを使用することで、日本のアニメ風のキャラクターイラストを生成できます。目や髪の表現など、アニメスタイルの特徴をよく捉えています。
製品デザインの生成例
プロンプト:
「minimalist coffee cup design, white ceramic, sleek handle, product photography on white background, advertising quality, studio lighting, sharp focus, commercial photography」
(ミニマリストのコーヒーカップデザイン、白いセラミック、スマートなハンドル、白い背景での製品写真、広告品質、スタジオライティング、シャープなフォーカス、商業写真)
ネガティブプロンプト:
「blurry, low resolution, amateur, crooked, distorted, uneven, text, logo」
(ぼやけた、低解像度、アマチュア、歪んだ、ゆがんだ、不均一な、テキスト、ロゴ)
設定:
- Model:Realistic Vision
- Sampling method:DPM++ SDE Karras
- Sampling steps:25
- CFG Scale:8
- Size:640×640

商品写真のような高品質な製品デザイン画像も生成可能です。ライティングや素材感など、プロダクト撮影の要素がよく表現されています。
これらはほんの一例で、プロンプトや設定を調整することで、さまざまなスタイルやジャンルの画像を生成できます。実際に試してみて、自分の表現したいイメージに合う設定を見つましょう。
Stable Diffusion Web UIを使いこなすコツ
Stable Diffusion Web UIでより良い画像を生成するためのコツをいくつか紹介します。
効果的なプロンプトを作成する

プロンプトは画像生成の中心となる重要な要素です。以下のポイントを押さえることで、より意図した画像に近づけられます。
- 具体的な描写を心がける
- 「美しい風景」より「夕日に染まる雪山と青い湖」のように具体的に
- 主題、背景、光の状態、天候などの要素を盛り込む
- 画風や品質を指定する
- 「photorealistic」「oil painting」「anime style」など画風を指定
- 「detailed」「high quality」「masterpiece」などの品質キーワードを追加
- 重要キーワードに重み付けをする
- (keyword:1.5) のように括弧内に数値を付けて重要度を調整
- 主題に1.2〜1.5程度の重みを付けると強調される
- 構図や視点を指定する
- 「close-up」「wide shot」「aerial view」など視点を指定
- 「symmetrical composition」「rule of thirds」など構図に関するキーワードも有効
- ネガティブプロンプトを活用する
- 避けたい要素を明確に指定(「blurry, distorted, low quality」など)
- 特に人物画像では「bad anatomy, bad hands, extra fingers」などを指定すると効果的

上:簡易的なプロンプト「Mountain, Lake, Sunset」(山、湖、夕日)、ネガティブプロンプトなし
下:詳細なプロンプト「beautiful mountain landscape with a lake, snow-capped peaks, reflection in water, sunset colors, photorealistic, detailed vegetation, 8k, masterpiece」
(美しい山の風景、湖があり、雪をかぶった山頂、水面に映る反射、夕日の色彩、写真のようにリアルで、詳細な植生、8K、傑作)
ネガティブプロンプト「bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality」(悪い解剖学、悪い手、欠けた指、余分な指、少ない指、切り取られた、最悪の品質、低品質)
生成画像に含めたい要素、あるいは排除したい要素を余すところなく入力するのが一番のコツです。
目的に沿ったモデルを選ぶ

目的に合った生成モデル(チェックポイント)を選ぶことで、生成結果が大きく変わります。
生成モデルは外部からのダウンロードが必要です。Stable Diffusion公式サイトやコミュニティなどでお気に入りのモデルを探してみましょう。
ダウンロードしたモデルはStable Diffusion WebUIをインストールフォルダ内の「models」→「Stable-diffusion」フォルダに保存することで使用できます。
保存後、生成モデルは以下のように画面左上のボックスから選択可能です。

| <各目的に合ったモデルを選択> 写実的な写真風画像:Realistic Vision、Deliberate、SDXL アニメ・イラスト:Anything、Counterfeit、Waifu Diffusion 風景特化:Dreamshaper、SDXL Turbo 人物特化:ChilloutMix、Realistic Vision |

プロンプト:
minimalist coffee cup design, white ceramic, sleek handle, product photography on white background, advertising quality, studio lighting, sharp focus, commercial photography
(ミニマリストのコーヒーカップデザイン、白いセラミック、スマートなハンドル、白い背景での製品写真、広告品質、スタジオライティング、シャープなフォーカス、商業写真)
ネガティブプロンプト:
blurry, low resolution, amateur, crooked, distorted, uneven, text, logo
(ぼやけた、低解像度、アマチュア、歪んだ、ゆがんだ、不均一な、テキスト、ロゴ)

プロンプト:
portrait of a young woman, smiling, natural lighting, detailed face, soft skin, realistic eyes, high-quality photography, masterpiece
(若い女性のポートレート、微笑んでいる、自然光、詳細な顔、柔らかい肌、リアルな目、高品質な写真、傑作)
ネガティブプロンプト:なし
モデル選びは画像の仕上がりを大きく左右するので、自分の作りたいものに合わせて選ぶのがポイントです。Stable Diffusion WebUIはコミュニティモデルを試せる自由度が高い点も注目されてる点なので、いろいろ試しながらお気に入りのモデルを見つけましょう。
設定パラメータの調整をする

各種パラメータの調整も、生成結果に大きな影響を与えます。プロンプト入力欄の下にあるパラメータを調整して、理想の画像に近付けられます。
| <各設定パラメータの調整> サンプラー:「DPM++ 2M Karras」は汎用性が高い。「Euler a」はアニメ調に向いてい Sampling Steps:20〜30程度が一般的。高いほど細部が向上するが、時間がかかる CFG Scale:7〜12が標準。高いとプロンプトに忠実になるが不自然になることも Seed:気に入った画像のSeed値を保存し再利用すると、類似画像が生成できる |

画像生成後のテクニック

生成後の画像をさらに改善するテクニックもあるので、いくつか紹介します。
| <画像生成の質が上がるテクニック> アップスケール:「Extras」タブで低解像度画像を高解像度に拡大 顔の修正:「Restore faces」機能で人物の顔を自然に修正 ハイライト・シャドウの調整:img2imgで元画像にDenoising strength 0.3程度で再適用 複数画像の組み合わせ:「Inpaint」機能で複数画像の良い部分を組み合わせる |
現在のStable Diffusion Web UIでは、画像生成の回数に制限がありません。これらのテクニックを何度も試して、理想の画像を生成しましょう。
拡張機能の活用

Stable Diffusion Web UIは多数の拡張機能で、さらにできることが広がります。特におすすめの拡張機能には以下のようなものがあります。
| <おすすめの拡張機能> ControlNet:線画や姿勢、被写界深度などをコントロールできる強力な拡張機能 Dynamic Prompts:プロンプトのバリエーションを自動生成I mage Browser:生成した画像を効率的に管理・閲覧 Civitai Helper:Civitaiというモデル共有サイトとの連携を簡単にする |
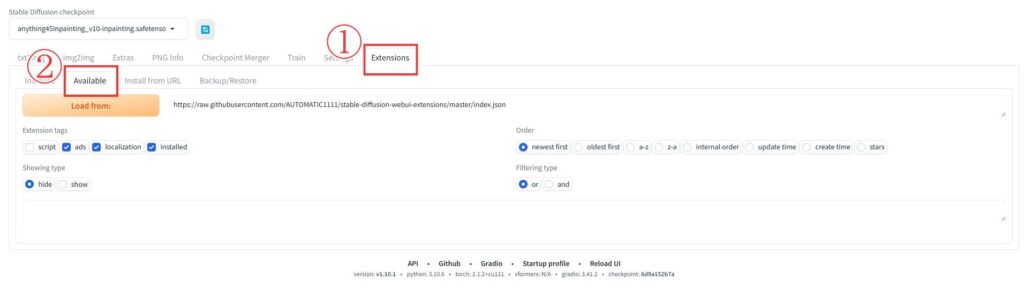
拡張機能は「Extensions」タブの「Available」から検索してインストールできます。
これらのコツを活用して、Stable Diffusion Web UIでの画像生成スキルを向上させていきましょう。試行錯誤を重ねることで、徐々に意図した画像に近づけることができるようになります。
Stable Diffusion Web UI のよくある質問
Stable Diffusion Web UIについて、ユーザーからよく寄せられる質問とその回答をまとめました。
Stable Diffusion Web UIは何回まで無料で使える?

Stable Diffusion Web UIは完全無料で、使用回数の制限はありません。ローカル環境で動作するオープンソースソフトウェアのため、インストールさえ済ませば、自分のPCのリソースの範囲内で無制限に使用できます。
クラウドベースのサービスのように、月間生成枚数の制限や、クレジット制度はありません。ただし、自分のPC(特にGPU)のリソースを使用するため、電気代などのランニングコストはかかります。また、生成速度や品質はPCのスペックに左右されます。
Stable Diffusion Web UI に必要なPCスペックは?

Stable Diffusion Web UIを快適に使用するためには、以下のようなスペックが推奨されます。
| <最低要件> GPU: NVIDIA GeForce GTX 1060 6GB以上 CPU: Intel Core i5-6600 / AMD Ryzen 5 1600相当以上 RAM: 16GB以上 ストレージ: 20GB以上の空き容量(SSD推奨) OS: Windows 10/11, Linux(Ubuntu 20.04以降推奨) <推奨スペック> GPU: NVIDIA GeForce RTX 3060 12GB以上 CPU: Intel Core i7-10700K / AMD Ryzen 7 3700X相当以上 RAM: 32GB以上 ストレージ: 50GB以上の空き容量(SSD必須) |
特にGPUのVRAM(ビデオメモリ)容量が重要で、これが多いほど大きなサイズの画像生成や複雑なモデルの使用が可能です。VRAM 6GB未満のGPUでも動作させる方法はありますが、かなり制限された機能になります。
MacのM1/M2チップでも動作させる方法はありますが、設定が複雑で動作も不安定なことがあります。本格的に使いたい場合は、NVIDIA製GPUを搭載したPCの使用をおすすめします。
Stable Diffusion Web UI でエラーが出たときの対処法は?

Stable Diffusion Web UIで発生する主なエラーとその対処法を紹介します。
「CUDA out of memory」エラー
- 原因:GPUのVRAMが不足している
- 対処法:
- 生成画像のサイズを小さくする
- Batch sizeを1に減らす
- 「–lowvram」または「–medvram」オプションを起動スクリプトに追加する
- アクティブなモデルを軽量なものに変更する
「Failed to initialize CUDA」エラー
- 原因:CUDA(NVIDIA GPUの計算プラットフォーム)の初期化に失敗
- 対処法:
- グラフィックドライバーを最新版に更新する
- NVIDIA Control PanelでプライマリグラフィックスプロセッサとしてNVIDIA GPUが選択されているか確認
- 起動スクリプトに「–skip-torch-cuda-test」オプションを追加
「ModuleNotFoundError」エラー
- 原因:必要なPythonモジュールが不足している
- 対処法:
- 「update」スクリプトを実行してモジュールを更新
- コマンドプロンプトで「pip install [不足モジュール名]」を実行
- 仮想環境を再作成する(上級者向け)
「ImportError: DLL load failed」エラー(Windows)
- 原因:必要なDLLファイルの読み込みに失敗
- 対処法:
- Microsoft Visual C++ 再頒布可能パッケージをインストール
- Pythonを再インストール
- システムを再起動
起動時に「続行するには何かキーを押してください」と表示され終了する
- 原因:インストールや初期化プロセスでエラーが発生
- 対処法:
- コマンドプロンプトの出力を確認し、具体的なエラーメッセージを特定
- webui-user.batファイルを編集し、「COMMANDLINE_ARGS=」の行に「–debug」を追加して詳細情報を表示
- GitHubのissuesページや公式Discordで同様の問題を検索
エラーが複雑で解決できない場合は、公式のGitHubリポジトリのIssuesセクションやDiscordコミュニティで質問すると、詳しいユーザーからアドバイスをもらえることがあります。







