
ChatGPTで自分が得たい情報をもっと的確に回答してほしい、と思ったことはありませんか。
効果的に活用するためには、その学習メカニズムやデータ学習方法を理解することが不可欠です。
本記事では、ChatGPTの学習メカニズムを解説し、特定の情報を学習させるための5つの方法やデータを学習させない設定方法について紹介します。ChatGPTに情報を学習させる際の注意点にも触れているので、ぜひ参考にしてChatGPTを使いこなしてください。
▶︎ChatGPTとは?使い方や画像付き活用例、料金プランなどを解説
ChatGPTの学習メカニズム
ChatGPTは、自然な言語生成を実現するために学習メカニズムを使用しています。
以下では、ChatGPTの回答生成の仕組み、学習方法、データの偏りと限界について詳しく解説します。
回答生成の仕組み

ChatGPTは、トランスフォーマー(Transformer)モデルを元にしています。このモデルは、大規模なテキストデータを使って言語のパターンを学習し、その学習結果をもとに新たなテキストを生成します。
具体的には、次のような手順で回答が生成されます。
- 入力テキストの解析
最初に、入力されたテキスト(プロンプト)がトークンと呼ばれる小さな単位に分解されます。トークンとは、単語や句読点などの最小の意味単位のこと。この処理により、ChatGPTはテキストの意味を理解します。
- 文脈の把握
その後、トークンごとにその前後の文脈がどのように関連しているかを解析。例えば、「犬」と打ち込むと、動物を指す可能性が高いと理解します。
- 予測と生成
トランスフォーマーのモデルは、それぞれの単語や句読点の次に来るべき単語を予測します。予測されたトークンは文脈に沿った適切な回答を形成するため組み合わさり、最終的な文章が生成されます。
この仕組みにより、ChatGPTはかなり高精度な回答を生成できるのです。
学習方法
機械学習には教師あり学習、教師なし学習、強化学習、深層学習の4つの主要な学習方法があります。それぞれの方法について詳しく見ていきましょう。
教師あり学習
教師あり学習は、最も基本的な学習方法です。何が正しいかラベルがついたものを使って学習していきます。迷惑メールを分類するシステムでは、「このメールは迷惑メール」「このメールは通常のメール」というラベルをつけたデータを使って機械を訓練します。この方法では、機械は人間が提供したマニュアルに従って学習し、未分類のデータに対しても正しいラベルを予測できるようになります。
教師なし学習
教師なし学習では、ラベルがついていないデータを使用します。機械は自分自身でパターンや規則性を見つけ、データを分類したり、構造を理解していきます。迷惑メールの例でいうと、ラベルがない大量のメールデータを使って、自分で「迷惑メール」と「通常メール」の特徴を抽出し、分類します。
強化学習
強化学習は、周囲の環境とのやりとりを通じて学ぶ方法です。ある行動を取ることで得られる報酬を元に、最適な行動を学んでいきます。例えば、囲碁や将棋のAIでは、最初にルールを教え、ゲームを通じて「勝つ」という報酬を目指して最適な手を学習します。ChatGPTのような会話型AIにも強化学習が活用されていて、人間からのフィードバックをもとに、より自然で適切な返答ができるように学習します。
ChatGPTでは以下のように出力した結果に対してフィードバックすることができます。

深層学習
深層学習は、脳の神経回路を模倣したニューラルネットワークに基づいています。このアプローチでは、複数の層がデータを受け取り、最終的な結果を出力します。深層学習の特徴は、中間層でデータの抽象化を行うため、複雑なパターンや特徴を自動的に学習できる点です
データの偏りと限界
ChatGPTは膨大なテキストデータを学習していますが、そのデータには必ずしもすべての情報が含まれているわけではなく、偏りが存在します。
インターネット上の情報には文化的、地理的、政治的な偏りが含まれていることがあります。ある特定の地域や文化に関する情報が豊富で、他の地域や文化についての情報が少ない場合、その影響で出力される内容にも偏りが生じることがあります。
また、ChatGPTは訓練後に新しいデータでの更新が行われないため、学習した時点での知識が固定されています。そのため、最新のニュースや科学的な発見に関して知識に不足があります。常に最新の情報とは限らないので注意しましょう。
ChatGPTに特定の情報を学習させる5つの方法
ChatGPTを学習させて、特定の情報や分野に特化させることも可能です。以下では、ChatGPTに特定の情報を学習させるための方法を5つ紹介します。
プロンプトを活用する
プロンプトとは、ChatGPTに入力するテキストのことです。プロンプトを工夫することで、特定の情報を学習させたかのような効果を得ることができます。
たとえば、自社の新サービスの資料を作成する際には、プロンプトにサービス情報を追加するとそれに沿った回答がもらえます。
「以下の弊社の新サービスの内容をもとに、商談で使える資料作成をお願いします」といったように、プロンプトに組み込むことで、より詳細な回答が得られるでしょう。
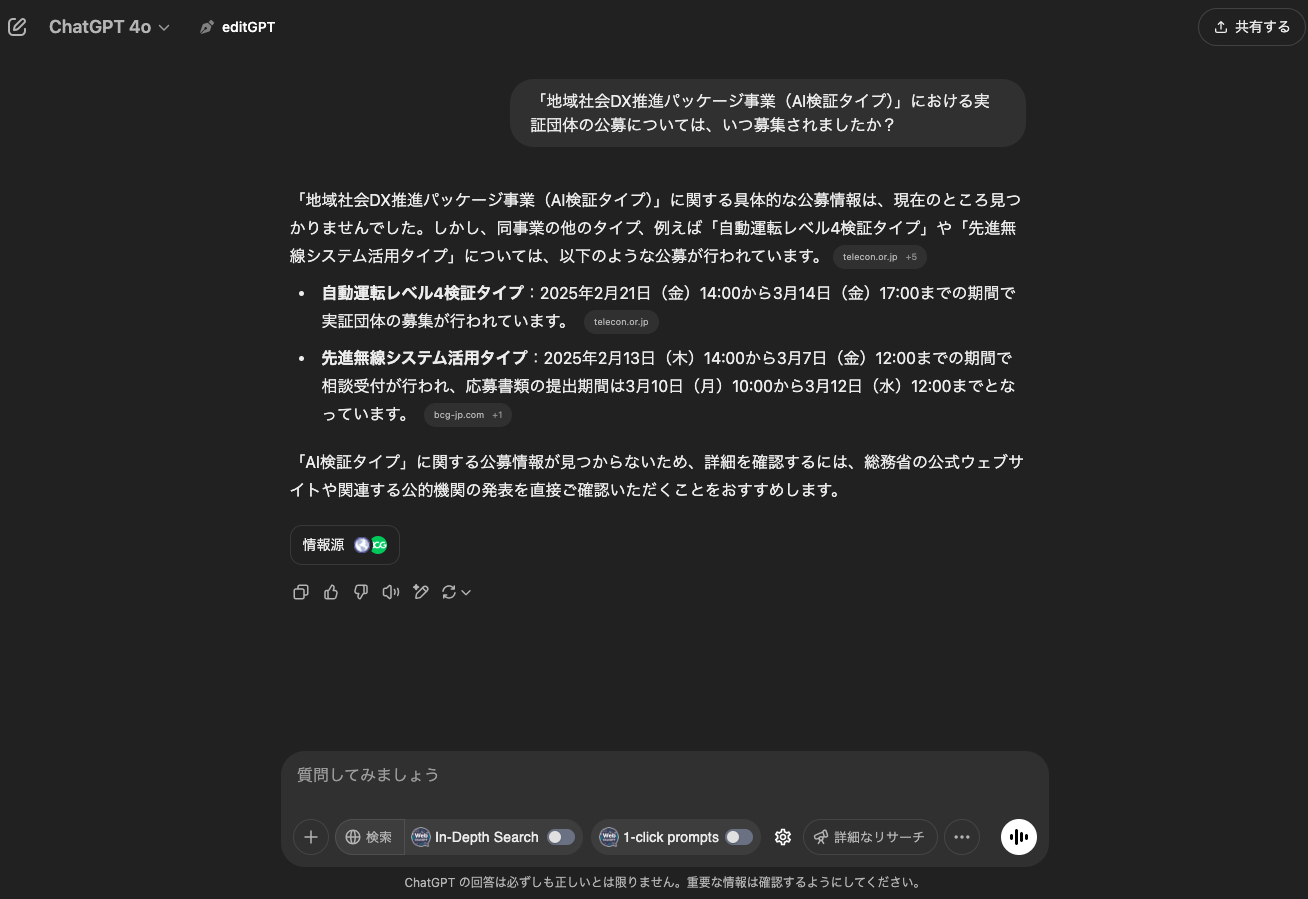
総務省が2月28日に公開したAIを用いた通信負荷の低減・通信量の確保等の検証に関する実証団体の公募について知っているかChatGPTに聞いたところ、正しい情報が出力されませんでした。
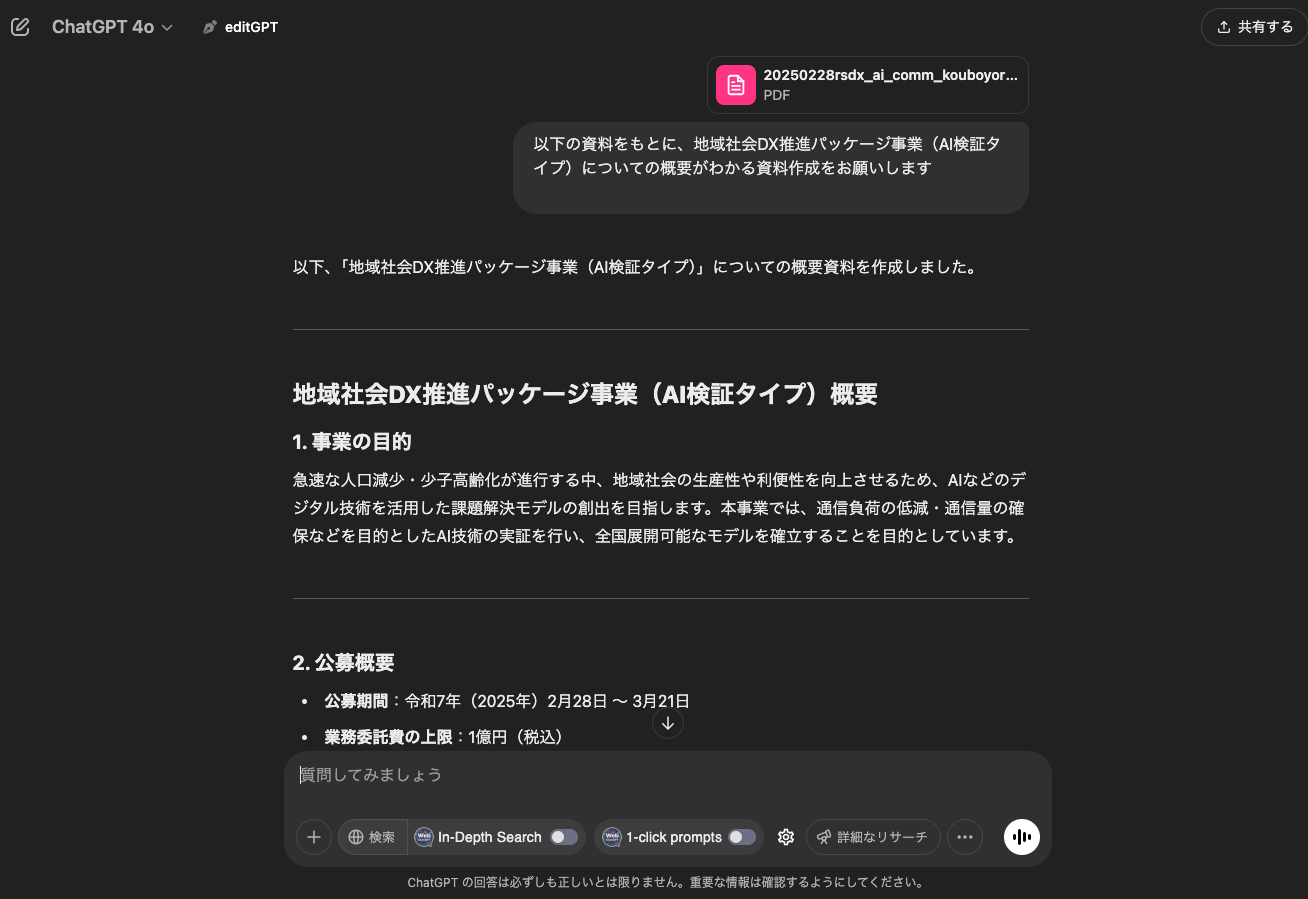
ChatGPTは情報を持っていませんが、「以下の資料をもとに、地域社会DX推進パッケージ事業(AI検証タイプ)についての概要がわかる資料作成をお願いします」と指示し、pdf資料を送りました。そうすると資料を読み込み、出力してくれます。
総務省「地域社会 DX 推進パッケージ事業」のうち「AI 検証タイプ」における実証機関の公募」というpdf資料を読み込みましたが、pdfの読み込み方は以下で詳しく説明しています。
▶︎ChatGPTにファイルを読み込ませる方法とは?手順やコツ、注意点について解説
簡単に取り入れることができるので、おすすめです。プロンプトによって出力の質が変わる点、情報をChatGPTに送信するのでセキュリティ面に注意する必要があります。
「ChatGPTにデータを学習させる場合の注意点」で詳しく解説します。
追加機能を使う
ChatGPTには、プラグインと呼ばれる機能を拡張するためのツールがあります。この追加機能を利用することで、特定の分野に特化した知識を持つモデルを作成できます。URL内の情報を取得して、要約や翻訳といった形で活用するWebPilotや、PDFファイルから情報を取得して、要約や翻訳などを通してデータを活用するChatWithPDFがあります。
しかし、OpenAIはChatGPTのプラグイン機能(ベータ版)を2024年4月9日に終了すると発表しました。
そのため、プラグインではなくGPTsの使用がおすすめです。
GPTストアの検索機能を利用して、自分が知りたい分野のGPTsを見つけて使用してみましょう。
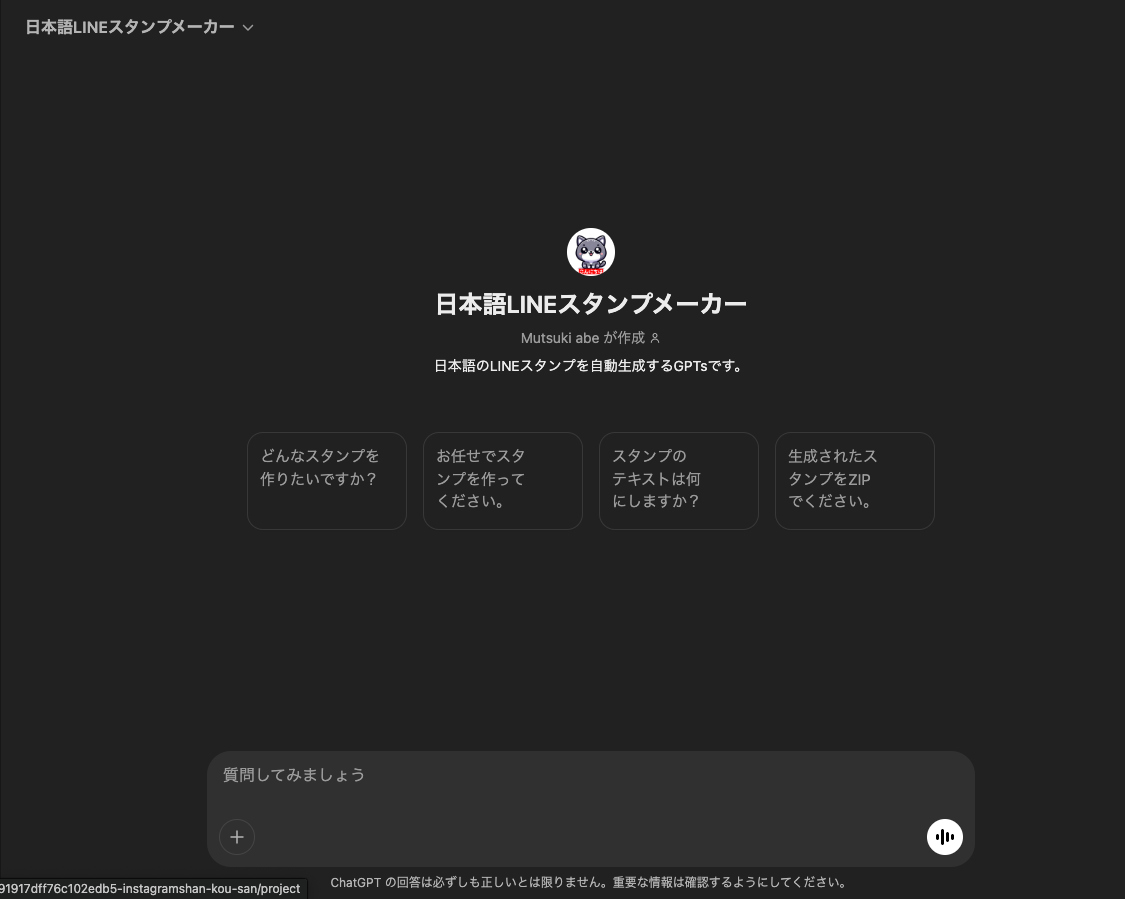
スタンプメーカーでは実際に画像を生成してくれます。
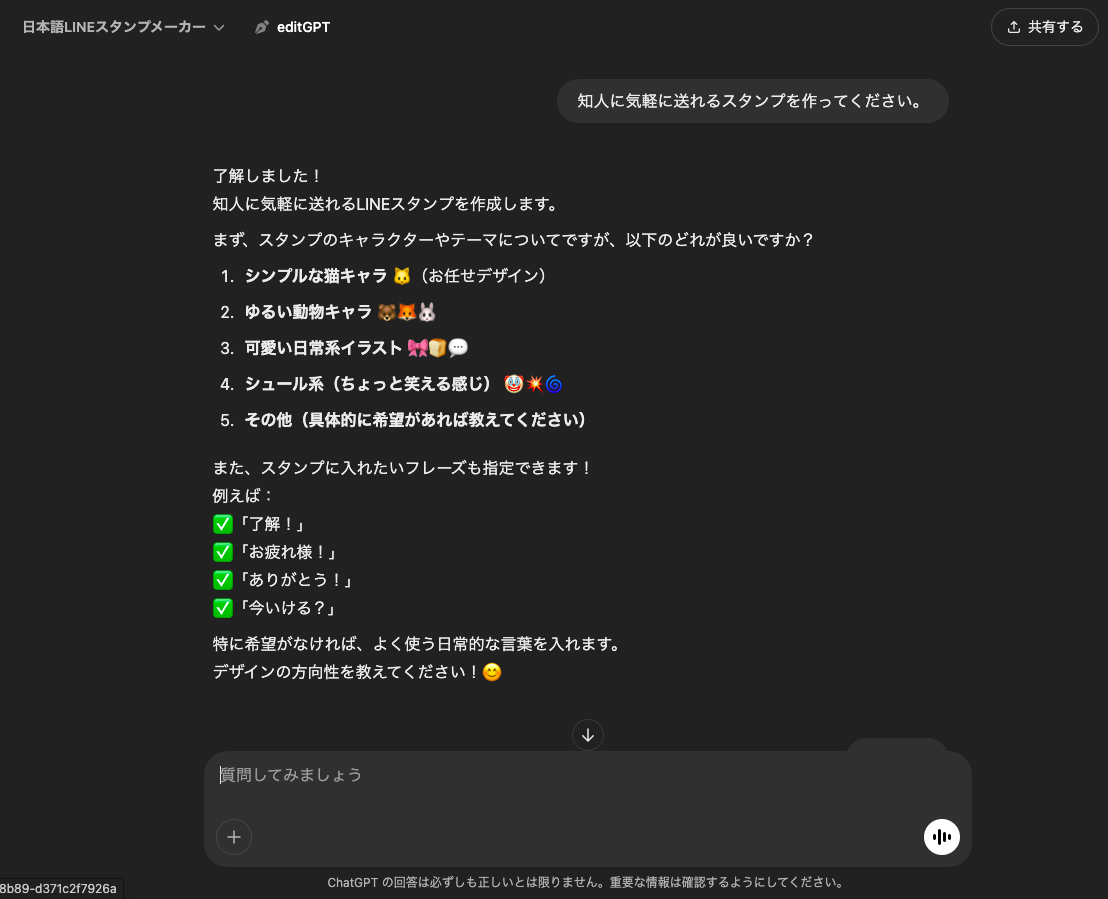
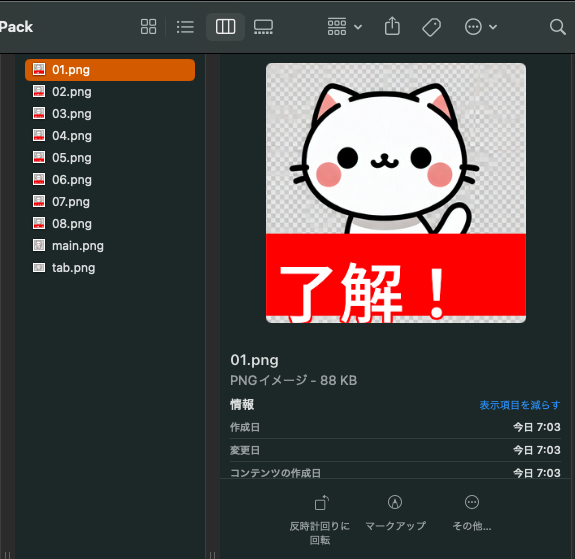
日本語LINEスタンプメーカーでは、「知人に気軽に送れるスタンプを作ってください」と送るだけで以下のように生成し、簡単にダウンロードすることができます。
自分向けに調整する
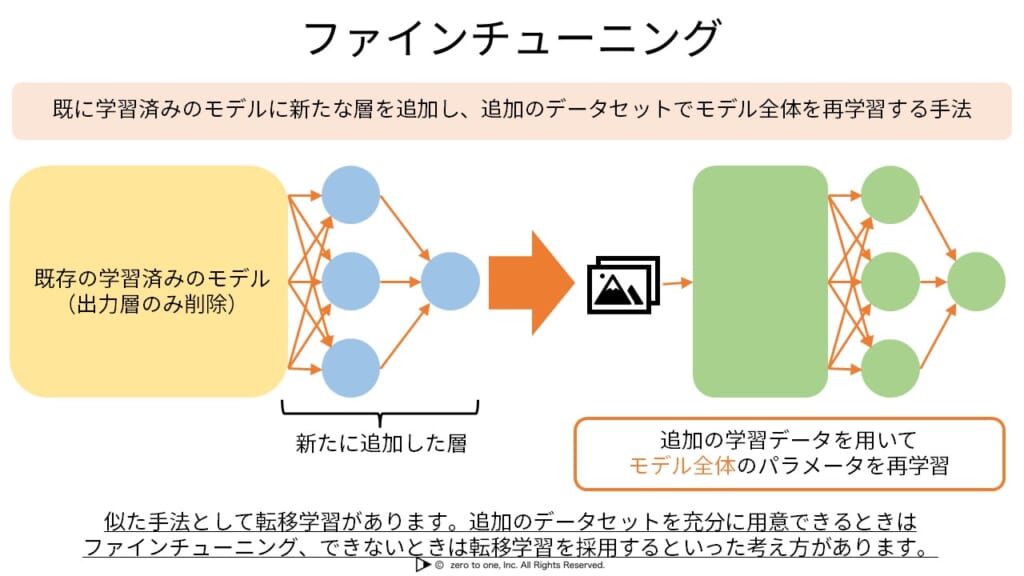
(出典:AI WORDS AI 用語集(G検定対応)ファインチューニング)
自分向けに調整する方法として、大量のデータを追加で学習させるファインチューニングという方法があります。ビジネスの質問に特化したモデルを作成するために、業界のFAQをプロンプトに含めることで、その分野に特化した知識を反映させることができます。
学習データの質と量が重要で、追加するデータによっては意図しない回答が出てきてしまいます。また、OpenAI APIを使用するため、プログラミングの知識が必要です。
APIを使ってデータを覚えさせる

Chat GPT APIを利用して、外部データをChatGPTに供給し、リアルタイムで情報を学習させる方法もあります。最新のビジネスデータベースやウェブサイトから情報を引き出して、ChatGPTに関連情報を与えることができます。最新情報やリアルタイムのユーザーの課題を引き出すことが可能です。
しかしAPIを使用するには、専門的なプログラミング知識が必要になります。自分で学ぶか、誰かに頼む形になるため、ハードルは高いといえるでしょう。
専用ツールを使う

ChatGPT専用のツールを導入することも1つの方法です。問い合わせ用のチャットボットや文章作成など、ChatGPTと合わせて使うことで業務を効率化できるサービスがあります。専用ツールを活用することで、カスタマイズされたFAQや専門的な知識ベースを使用し最適な回答を得られるようになります。
ChatGPTにデータを学習させない設定方法
ユーザーによっては、ChatGPTに特定の情報を学習させたくない場合もあるでしょう。以下では、PC版とスマホ版の設定方法を解説します。
PC版
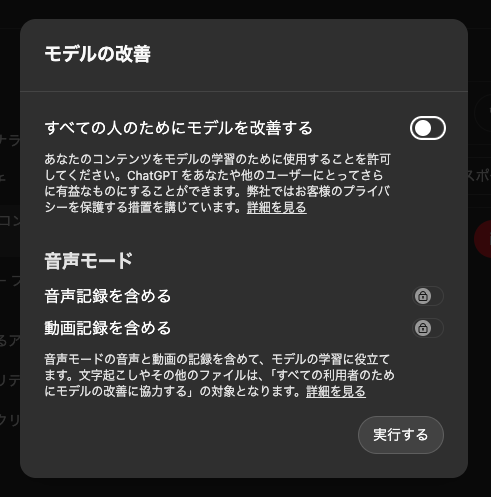
PC版でChatGPTにデータを学習させない設定を行うには、右上のアイコンをクリックし、設定を開きます。

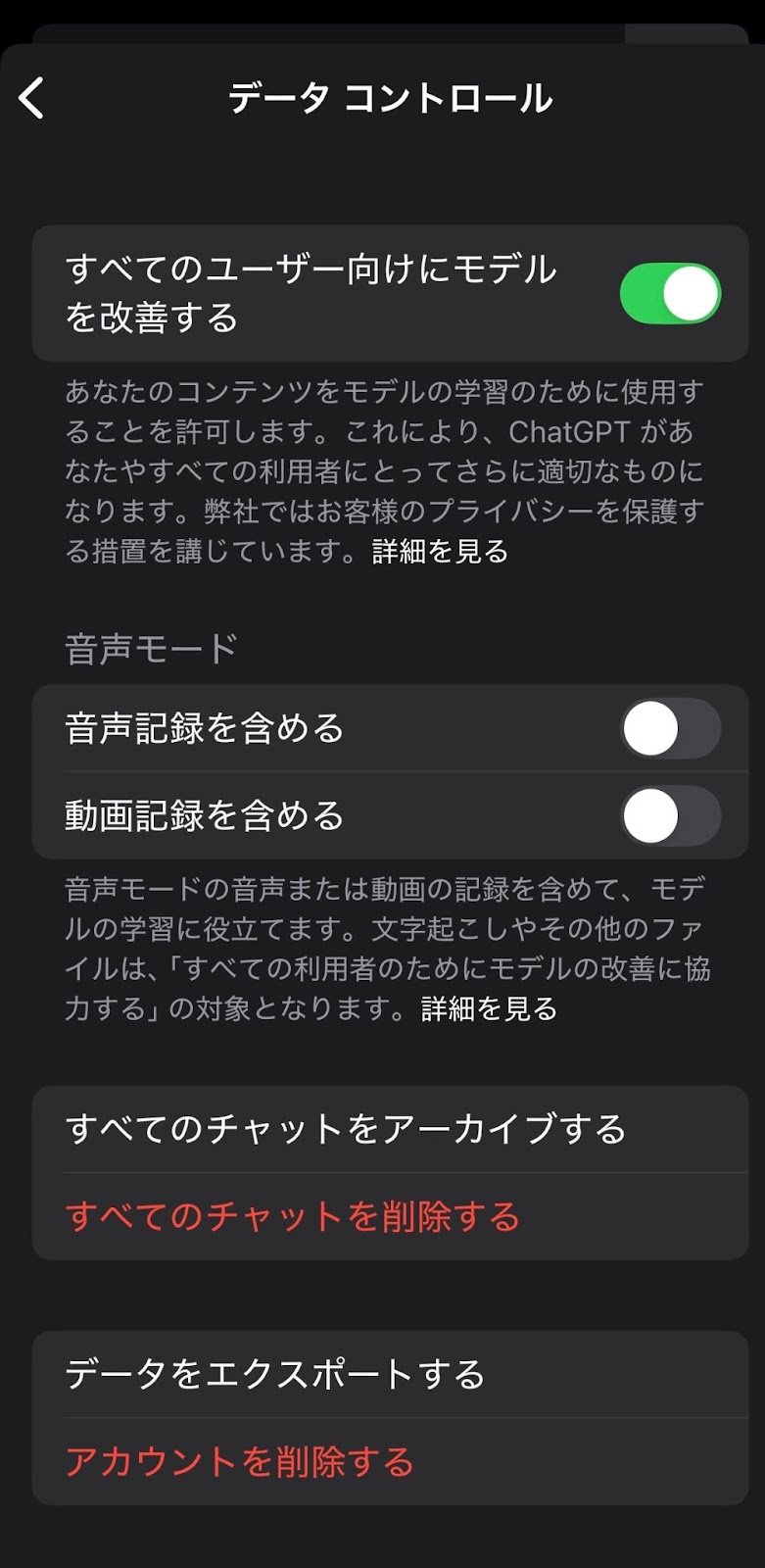
左側から「データコントロール」を選択し、1番上の「すべての人のためにモデルを改善する」をオフにします。

オンの状態の人は「すべての人のためにモデルを改善する」をクリック。チェックを外し1番下の「実行する」を選択すると設定が完了です。
スマホ版
スマホ版でも同様にアイコン横の「・・・」をクリックし、「データコントロール」を選択します。
1番上の「すべての人のためにモデルを改善する」をオフにすると設定できます。
ChatGPTにデータを学習させる場合の注意点
ChatGPTは便利なツールですが、データを学習させる際にはいくつかの注意点があります。特に、機密性の高い情報を取り扱う場合や、間違った情報が学習されるリスクを避けるために配慮が必要です。ここでは、ChatGPTにデータを学習させる場合の注意点を解説します。
情報漏洩を避ける

ChatGPTに特定のデータを学習させる際に最も重要なのは、情報漏洩を防ぐことです。特に機密情報や個人情報、企業の内部データを使用する場合、誤って外部に漏れないように十分に対策を講じる必要があります。
名前、住所、電話番号、クレジットカード情報などの個人情報は入力しないようにしましょう。これらの情報は、情報漏洩のリスクからプロンプトに入力するべきではありません。機密性の高い情報の入力も最小限にとどめるようにしましょう。API経由で情報を送信する際は暗号化された通信手段を使用することをおすすめします。
学習データの質に気をつける
ChatGPTの精度や信頼性は、学習に使うデータの質に大きく影響されます。質の悪いデータや誤った情報を学習させると、誤った回答を生成する可能性が高まります。学習に使用するデータには信頼性の高い情報源を選ぶことが重要です。インターネット上の誤情報や偏った意見を元にプロンプトを入力すると、誤った知識を学習し、意図しない誤情報を生成するリスクが高くなります。
また、データの偏りにも注意が必要です。ChatGPTは大量のデータから学習するため、データには偏りが生じることがあります。特定の文化圏や国に特化した情報が多ければ、他の文化や国についての知識が不足する可能性があります。そのため情報選びに注意し、偏りを最小限に抑えることが重要です。
ChatGPTに学習させるデータは定期的に更新しましょう。特に業界のトレンドや新しい知識が増えている分野では、常に最新の情報を取り入れ、精度を高める必要があります。
コストがかかる場合がある
APIを利用する場合や専用ツールを使用する場合には、追加のコストが発生します。
APIを利用する際には、リクエスト数や処理量によってコストが増加します。例えば、大量のデータセットを学習させる場合、APIの使用量が増えるため、その分のコストがかかります。また、専用のツールやプラットフォームを使う場合、ツールの月額料金やライセンス料が発生します。
費用対効果を確認しましょう。高度な学習機能を活用する場合、その投資がどれだけ有効かを見極めることが必要です。コストに見合った方法で、学習方法やツール選定を行いましょう。







