
Midjourneyから始まった生成AIブームが続く中、「そういえば生成AIってどういう仕組みで動いているんだろう?」と疑問に思った方もいるのではないでしょうか。
多少専門的な用語が入ることもありますが、都度かみ砕いて解説をしていきます。
ほかサイトで調べるよりも分かりやすく!を意識していますので、気になっているけど詳しくはないんだよなぁ……という方も安心してお読みください。
本記事で言及していく部分をざっくり書き出してみましょう。
- 生成AIってそもそもどういう定義なの?
- 生成AIが動作するのに利用されている学習方法は?
- 生成AIを活用しているサービスや技術って何があるの?
- 生成AIのモデルって何がある?
- 生成AIをもっと活用するためにできることは?
これらの点に関して、一度でも疑問に思ったことのある方はぜひ気になるところから読んでみてくださいね。
生成AIとジェネレーティブAI
クリエイティブではないの?と思う方もいるかもしれませんので、簡単に意味を捉えてみましょう。
まずクリエイティブとは、英辞郎によると以下の意味です。
1.創造力がある、創造性に富んだ、この点は「人間が」と書かれていますね。
では2や3の意味ではないのかと思うかもしれませんが、これは「被造物」が対象となっています。
生成AIの場合に置き換えると、生成AI自身の独創性に言及しているのではなくて「出力結果の」独創性に言及している、ということになりますね。

ではジェネレーティブ。同じく英辞郎で調べてみましょう。
クリエイティブより少々イメージがしづらいですね。
しかし、ここでは2の意味に注目してみるとよいでしょう。
言語学的な、と注意書きがありますが、「生成的な」というのはストレートです。
生成AIと聞いてイメージするであろうChatGPTやGeminiに関しては、特にこの意味がぴったりです。

ジェネレーティブは「創造する側のもの」を指し、クリエイティブは「創造される側のもの」を意味するということが理解頂けたかと思います。この違いから、生成AIはジェネレーティブAIとも呼ばれるのですね。
生成AIの定義
さて、言語として意味を理解頂けたところで、生成AIという言葉の指すものが一体何なのかを確認してみましょう。
簡単に言うと、生成AIとは「さまざまな学習方法によって人が作り出すような文章や画像、音楽、動画などのデジタルコンテンツを作成してくれるAI技術」です。
既存のコンテンツを提案するのではなくて、新しいコンテンツを生成する。
これが「生成」AIであると言えるポイントになります。
大量のデータを基にして学習を行い、学習した結果を出力する。これだけなら、「AI」にもできるからです。
つまり、生成AIが生まれた背景と動作する仕組みには、どちらも「自ら」「新しいものを」作り出す技術が関わっているということです。
生成AI誕生の経緯
生成AIが誕生するまで、AI技術を支える学習方法は「機械学習」と呼ばれるものでした。
大量のデータをコンピュータに与え、様々な条件付けを行ってそのパターンを学ばせる、というのが主な使い方です。
メールボックスに届く大量のメールを、ラベルや受信ボックスで分類するように設定する。
これが最も想像のしやすい「機械学習」の方法論かと思います。
そして、生成AIが誕生したきっかけと言えるのが「深層学習」という手法が確立したことです。
深層学習は従来の機械学習の発展したものであり、大量のデータをコンピュータに与えるところまでは変わらないものの、その後の条件付けやパターンの学習を自動で行うことができるようになりました。
これによって、AIにも「0から1を生み出す」ことが可能になったというわけです。
深層学習について
AIに対する学習方法は様々あります。
「教師あり学習」というと、正解のデータを与えたうえで未知のデータを予測できるようになるというものです。
「教師なし学習」は、対照的に正解のデータを用意しない手法です。
クラスター分析や主成分分析などを調べて参考にすることで、「教師なし学習」とは何か、についても知ることができます。
また、他の学習手法としては「強化学習」と呼ばれるものもあります。
これは効率化や最適化に関しての視点で重要視されるものとなり、AIにデータを処理させた後その結果をスコアリングすることで、スコアが最大になるようにAIが学習していく形式ですね。
そして、与えられたデータそれぞれに共通する特徴をピックアップする技術が「深層学習(ディープラーニング)」です。
すでに学習したデータを参考にした解答だけでなく、AI自身が学習し続けることで人間が与えたデータ以外にも新しい情報やデータを取り入れ、それを基にした創造性の高いアウトプットを人間に引き渡すことができます。
深層学習は他の手法と比べて非常に「たくさん学習する」のが特徴です。
どうしてたくさん学習できるのかというと、学習する内容の特徴をとらえて、ある程度自力で学習方法を考えることができるからです。
AさんとBさんの顔の特徴が似ていると気づけるかどうかで、AさんとBさんが兄弟であるかどうか、と考えられるかが決まりますね。深層学習はこの例のように、他の方法では気づきにくい特徴に気づけます。
だからこそ、できることがあります。
画像のような記号化できないものもパターンとして認識できるというところ、これが深層学習の強味です。
学習データに画像を含めることができるようになったからこそ、画像生成AIや動画生成AIが生まれたというわけですね。
AIの強弱
AIには、「強いAI」と「弱いAI」があります。
生成AIのように特定のタスクに特化したAIは弱いAIに分類されます。
これは他の用途に利用することができない、汎用性がないという意味ですが、日々進歩を遂げているのでいつか強いAIに分類される日も来るかもしれません。
では、「強いAI」とは何でしょう。
代表的なものは「AGI(汎用人工知能)」と呼ばれるものです。
現時点ではまだ確立されていない、概念上の存在ですが、概念を理解しておくことは重要です。
2045年には技術的特異点(シンギュラリティ)が発生して、社会にとってのAIが予測不可能な影響を及ぼすものになる、という仮説も提唱されています。
生成AIの種類
生成AIと一口に言ってもさまざまな種類がある、ということは皆さんご存じでしょうが、一度おさらいしておきましょう。
文章生成AI
OpenAIが開発した「ChatGPT」、Googleの提供する「Bard」や「Gemini」。
これらが文章生成AIです。特徴としては、指示を与えるプロンプトが文章であるということ、それにたいする結果の出力も文章である、ということです。
アイデアの創出や文章の要約、プログラミングのコード生成などの作業をある程度自動化することができますが、ファクトチェックや出典の確認にもパワーが必要であるという難点があったりもします。
文章生成AIには、特に言語のベクトル化と呼ばれる技術も利用されています。
「BoW」や「Word Embedding」といった技術の活用によって単語の出現頻度から重要度を予測したり、単語同士の関係性から文章の意味を推測することができるようになったりするのです。
画像生成AI
「Stable Diffusion」、「Midjourney」、「DALL·E 」、「ImageFX」などが画像生成AIとして有名ですね。
指示を与えるプロンプトは文章ですが、それによって出力される結果が画像であるものを指します。
例えば、以下のような画像を作成することができます。
これを作成するのに使ったプロンプトは「生成AIの効果を象徴するような、青い背景の画像」です。
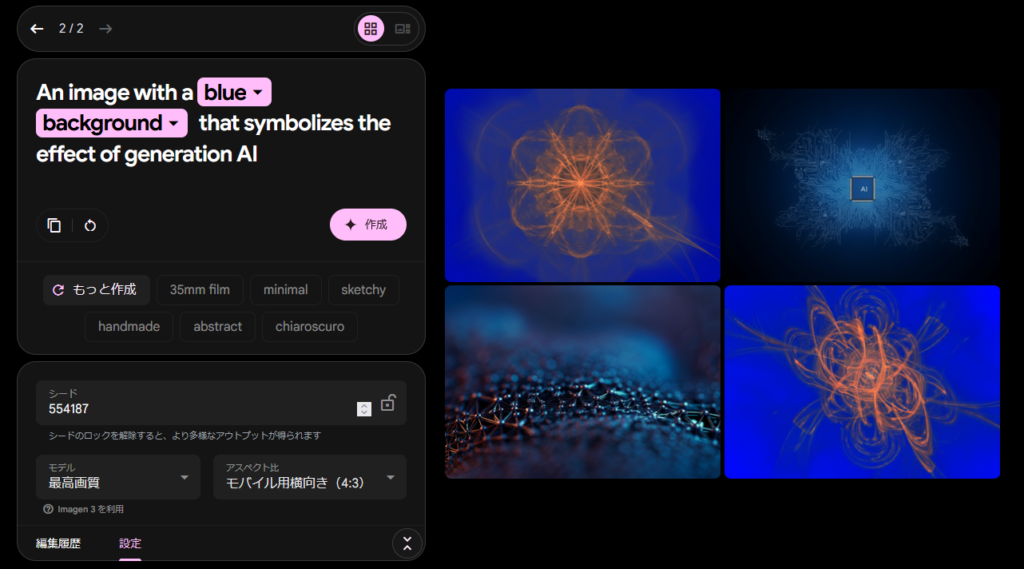
いまひとつイメージ通りではないと思った方もいるでしょうが、これは生成AIの特徴の一つに「推測」できるという点があるためと思われます。
「象徴するような」というワードを受けて、生成AIは抽象的な画像を作成したのだと思われます。
ちなみに、画像のベクトル化という技術も存在します。
画像を形と色の二要素に分けて、ベクトルに変換する技術のことです。
言語のベクトル化のように、画像を数学的に表現することで画像の拡縮に強く、画質の劣化を防ぐこともできるほか、そのデータをAIに学習させることで新しい画像を生成することもできるようになりました。
動画生成AI
「Gen-2」が登場してから、この動画生成AIに対する認知も深まったのではないでしょうか。
2023年3月にリリースされたものですが、生成AIの中でも特に開発の難易度が高いと言われているものなので、これから発展していくであろう部分として期待の分野です。
現在は数秒ほどの短い動画を生成する程度のものですが、おそらくは次第にそこそこ時間のある動画も作成できるようになったり、簡単なプロモーションビデオの作成であれば問題なく可能なようになるのではないかとも言われています。
音声生成AI
「VALL-E X」や「CoeFront」などのサービスに代表される音声生成AIは、テキスト入力から新たな音声を作成することができます。ものによっては、入力が音声でも可能なものもありますね。
たとえばですが、特定の1人の声を学習させることによって、その人の声と同じ声で、さまざまな文章の読み上げを行うことができるようになったりします。
声優業界などで一部問題視する声があがっていた時期もありますが、それは「本人の声を収録せずに」読み上げが可能になったりするという点によってです。
権利や収益などの問題がクリアになれば、この分野でもAIが発展していくと思われます。
生成AIに用いられるモデルの例
これらの生成AIには、それぞれ用途や理論の異なる様々なモデルが利用されています。
生成AIの仕組みを理解するうえでモデルの話は避けて通ることができませんので、代表的なものを紹介していきましょう。
GPT
開発元はアメリカのOpenAI。
ChatGPTの名前が非常に有名ですので、それに使われているものだという認識が一般的なのではないでしょうか。
現在ではGPT-4までリリースされていますが、最新版は有償ですので、無償利用ができるのは3.5が最新ですね。
非常に高度な自然言語処理能力を持っており、それゆえに人間が書いているかのような、自然な文章を出力することが可能です。
バージョンアップと共に進化していくものではありますが、無償版を利用している方でも実感しているのではないでしょうか。
GPT-4はアメリカの司法試験に合格できるほどの知能を有しているとも言われていることからも、処理能力の高さをうかがい知ることができますね。
最近の話ですが、検索をした際にこういった画面を見たことはないでしょうか。
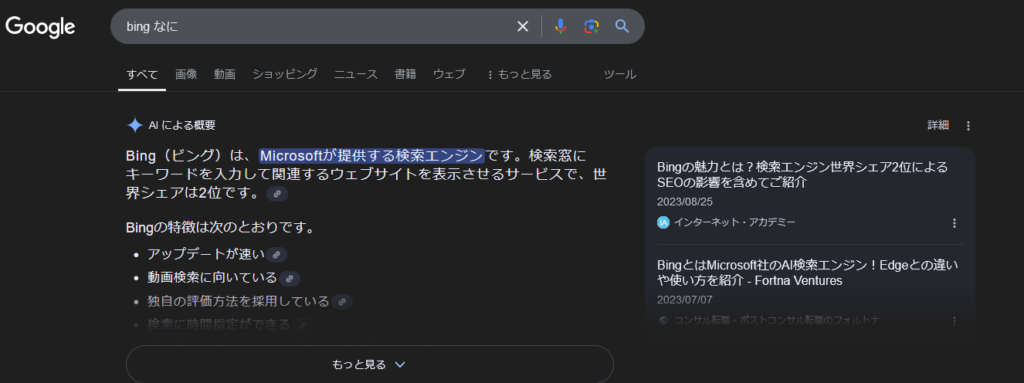
Microsoft社が提供しているbingとGPTが連携したため、検索エンジン上でGPT-4を融合したAIを使用することができるようになったため、Edge利用者でこういった画面を見かけている方は、GPTが非常に身近な方であるといえます。
VAE
画像生成AIに利用されているモデルの中でも、特に複雑な処理に強いのがVAEです。
正式には「Variational Auto-Encoder」といいます。
これには「変分オートエンコーダ」という深層学習の中のひとつの技術が活用されており、非常に利便性が高いというのが特徴です。
ざっくりというと、学習用データの特徴を抽出して、その性質を持った画像を生成する、という点に特化しています。
VAEモデルを利用している画像生成AIにゴッホの絵をたくさん与えたら、ゴッホのタッチに似た画像を生成してくれるようになる、というような感じです。
イラストレーターなどの職業においては特に著作権の侵害などで問題視されることも多いですが、許諾や法整備などによって今後大きな発展を遂げることもあるかもしれません。
GAN
画像生成AIに利用されているモデルの中でも、特に高解像度な画像の出力に強いのがGANです。
VAEとの大きな違いには「画像を生成する際の流れ」があります。
VAEが「変分オートエンコーダ」であるのに対して、GANは「生成器と識別器の競合」によって、より高度な画像を生成します。使用するネットワークが2つになっている、という点だけに着目しても、違いがあることが分かるでしょう。
「生成器」とは、ランダムに生成された画像のことを指します。
それに対して「識別器」とは、いわばお手本のようなものです。
ランダムに生成した画像をお手本と照らし合わせて、それにより近づこうという試みを繰り返すことで、高解像度の画像を作成することが可能になっている、というわけですね。
拡散モデル
画像生成AIに利用されているモデルの中でも、特に高解像度な画像の出力に強いのがGANである、とお伝えしましたが、拡散モデルはそのGANの進化した姿ともいえるものです。
現在ではかなり一般的に利用されている技術ですが、具体的な仕組みを知っている方は多くないかもしれません。
このモデルでは、画像がノイズで拡散していく過程と、そのノイズだらけの画像を復元する過程が重要になります。
ここでいう「拡散」を簡単に言うと「壊れ方」です。
拡散モデルを利用した生成AIは、「建物(画像)が壊れていく過程と組み立てられていく過程を勉強する」ことによって、「建物(画像)の作り方」を学びます。
家を建てる途中にトイレを増設する、のと同じ考え方で、「トイレのある家」の画像を生成します。
そう考えると、画像生成AIが時々よくわからない混ざり方をした画像を作ってくることにも、納得ができるのではないでしょうか。

生成AIを最大限に活用する「ファインチューニング」
ファインチューニングという技術を聞いたことがある方はいるでしょうか。
簡単に言うと、「汎用性の高い生成AIに更に情報を与えて、企業内のデータや最新のデータを参照できるようにする」手法です。
基本的には、提供されているChatGPTなどのサービスはWeb上の様々なデータを収集しています。
つまり、企業内のデータや最新のデータはまだ学習元として収集されていないので、それを基にした結果の出力はできない、というのがデフォルトの挙動です。
例えば、ChatGPTの無料版で提供されているGPT-3.5は、2021年9月までのデータを参照しています。
それ以降のデータは存在していませんので、例えば2024年にリリースされるサービスに関する情報を入力しても、結果は得られません。
そこで、それ以降の情報を追加で学習させる、というのがファインチューニングの基本的な考え方です。
実際の方法は学習データの作成、それをOpenAIのサイトにアップロードして読み込ませる、その結果を出力させる。という手順になるのですが、データの作成の段階から{“prompt”:”〇〇〇”,”completion”:”〇〇〇”}などの細かい様式の話にもなってきますので、興味のある方は調べてみてください。
まとめ:生成AIの仕組みを簡単に考える
さて、それではこれまでのまとめに入っていきましょう。
- 生成AIの仕組みは「学習→プロンプト(入力)→推論→出力」
- 学習方法には「教師あり学習」、「教師なし学習」、「強化学習」、「深層学習」などがある
- 深層学習の手法が確立したことによって、生成AIが誕生した
- 生成AIが利用しているモデルの代表例は、VAEやGPT、GAN、拡散モデルなど
- 最大限の活用のためには「ファインチューニング」の利用も検討
以上、生成AIの仕組みでした。
今後も実際にプロンプトを作成するときに気を付けるとよいこと、大学での活用例や生成AIにまつわる疑問についてなど、さまざま記事を作成していく予定ですので、もしお気に召したならブックマークなどで見逃しのないよう工夫いただけると嬉しいです。







