
2024年は、生成AIが急速に発展して、毎日のように新しいAIのニュースがリリースされていますね。
ChatGPTやGoogle Geminiをはじめとする生成AIの普及により、多くのビジネスマンや個人単位でもAIツールを日常的に活用するようになりました。
一方で、「検索までは早いけど、正確な情報なのかな?」と不安の声も聞こえてきます。今回は、AIの嘘と言われる”ハルシネーション”について、解説します。
生成AIの性格とハルシネーションについて理解して、効率的に生成AIを活用してくださいね!
AIが「嘘をつく」のはなぜ?
AIの生成の普及に伴って便利になった反面、誤った情報や架空の情報が生成されてしまったケースも発生しました。
例えば、2024年アメリカでは、法律関連の質問に対してAIが存在しない判例を参照したり、企業の製品開発においても、AIが生成した虚偽情報で裁判になったことで、問題となってしまったケースもありました。
AIは、その性格を理解して上手に活用すれば、人間では到底敵わないスキルを発揮してくれます。
こちらは、ハルシネーションの大まかな分類ですが、これらに注意しながらAIを活用していく必要があります。
ハルシネーションの分類
| 種類 | 説明 |
|---|---|
| 言語的ハルシネーション | AIが生成するテキストに事実と異なる内容が含まれる |
| 視覚的ハルシネーション | AIが生成する画像に現実にはありえないものが描かれる |
| 音声的ハルシネーション | AIが生成する音声に、実際には発せられていない言葉が含まれる |
ここからは、AIの出力する情報をどのように検証し、安全に活用していくべきか理解して、その対策方法について詳しく説明していきます。
大規模言語モデルの基本的な仕組み
生成AIは、大規模言語モデル(LLM)と言って、人間のような自然な言葉の理解と生成を可能にする、AI技術の核となるものです。
モデルは本質的に「パターンマッチング」と言われる、データの中から特定のパターンと一致する部分を検出する処理技術と「確率的な予測」に基づいて動作しています。
要するに、AIが、「過去のパターン」と「これが来るであろう」という確率を読んで、回答をしているというわけですね。
つまり、AIは人間からの質問をもとに、AIが知りうる学習データの中から最も適切だと判断した情報を組み合わせて回答を生成しているわけで、人間のように、事実や事例をもとに理解した回答を返しているわけではありません。
確率が高いものを選んでいく生成AI

このように、AIが蓄積していった学習モデルから、「次の単語はこうであろう」と予測して選択しています。
人間側が、AIは、内容の正誤の判断までできるわけではないという性格であることを理解して、事実は人間が精査した上で活用することが必要です。
AIの嘘「ハルシネーション」はなぜ起こる?
先ほどお伝えしたように、AI は生成されるデータから学習して、確率と前例で答えを出すため、誤った情報が生成されることがあります。
特に以下の 3 つの問題が主な原因として挙げられます。
- トレーニングデータの品質問題
- 更新データのタイミング
- 文脈理解の限界
これらについて解説していきます。
1.トレーニングデータの品質問題
AIは、学習していく中で、インターネット上の大量のテキストデータを使用します。
しかし、このデータには様々な誤った情報が含まれています。例えば、SNSでの誤った情報の拡散や、十分な事実確認がまた、過去には正しかったもの、現在では正しくない情報も含まれています。
こちらのX(旧Twitter)のポストでは、AIは、ユスフ選手に子供がいないと言っているが、実際にはお嬢様がいらっしゃると、事実と違うことがアウトプットされている例になります。
AIは、多くのデータを集めて、確率論で予測しています。このような結果を見ると、しばらく、事実確認は人間の手で行う必要がありますね。
2. 更新データのタイミング
AIの学習データには、時期的な制限があり、最新の情報が反映されないという問題があります。
「最新情報」というと少し抽象的な表現ですが、最新の技術発展や研究成果、統計データや法規制の更新などの学習データをさしています。
AIのバージョンや、AI自体も、常に最新なデータから学習しているわけではないため、古い情報に基づいた回答を生成してしまうことがあります。
3.文脈理解の限界
AIも、かなり人間らしい会話ができるようになってきて、言葉の表面的な意味も理解できますが、その背景にある微妙なニュアンスの理解は苦手です。
例えば、下記のようなものと考えてみてください。
- 「検討させていただきます」は断りの意味なのか、本当に検討するのかの区別
- 上司からの「できれば」「なるはや」という言葉が持つ実質的な指標や頃合い
- メールの文面から相手の本当の意図を考えること
本音と建前を汲み取ったり、感情や情緒を察したりという繊細なニュアンスは、人間独特なものですよね。
まだ、AIの学習データには「ニュアンス」という概念自体が理解されないことが多く、クライアントとの大事な商談や、社内の人間関係に関わる繊細な状況など、相手の温度を読み取りながら進める重要な打ち合わせや判断は、人間で進めた方が良いでしょう。
AIの誤った情報を見るためのチェックポイント
AIを使うと、分析や情報収集、資料作成するために便利なツールとして使えますが、時間をかけずにAIが導いた回答は鵜呑みにせず、しっかり確認することが大切です。
この記事では、AIの情報を正しく判断するためのポイントを解説していきますので、ぜひチェックしてくださいね。
出力内容の一貫性の確認
AIに質問して、瞬く間に出力される回答は、一見すると論理的に見えてしまいがちです。
よく見ると、文中で一貫性がなかったり、前後関係が崩れている場合があります。たとえば、最初に示した主張と後半で提示される理由が食い違っている、あるいは同じ情報が矛盾する形で繰り返されるといったケースです。
例としてこちらをご覧ください。
少額投資非課税制度であるNISAをAIで調べたところ、日本語がおかしいところがあります(赤丸内)
非現金の部分は、通常「非課税」とするところですね。
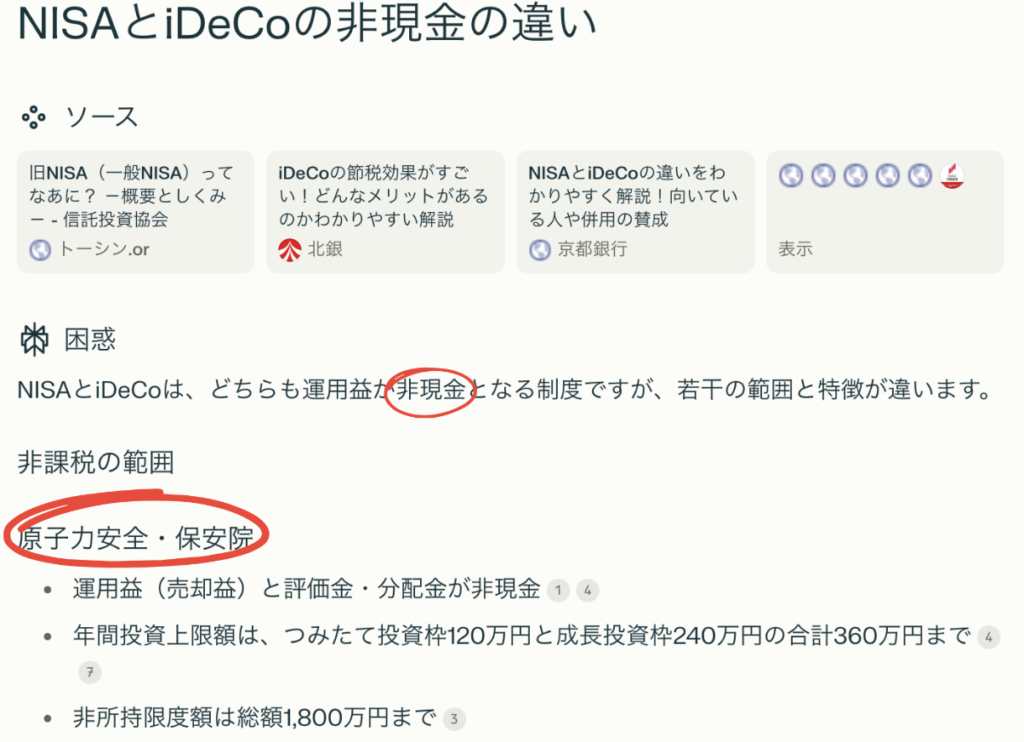
また、少額投資非課税制度を調べているのに「原子力安全・保安院」と明らかに相違が見られます。
こういった場合は、AIに質問してみます。
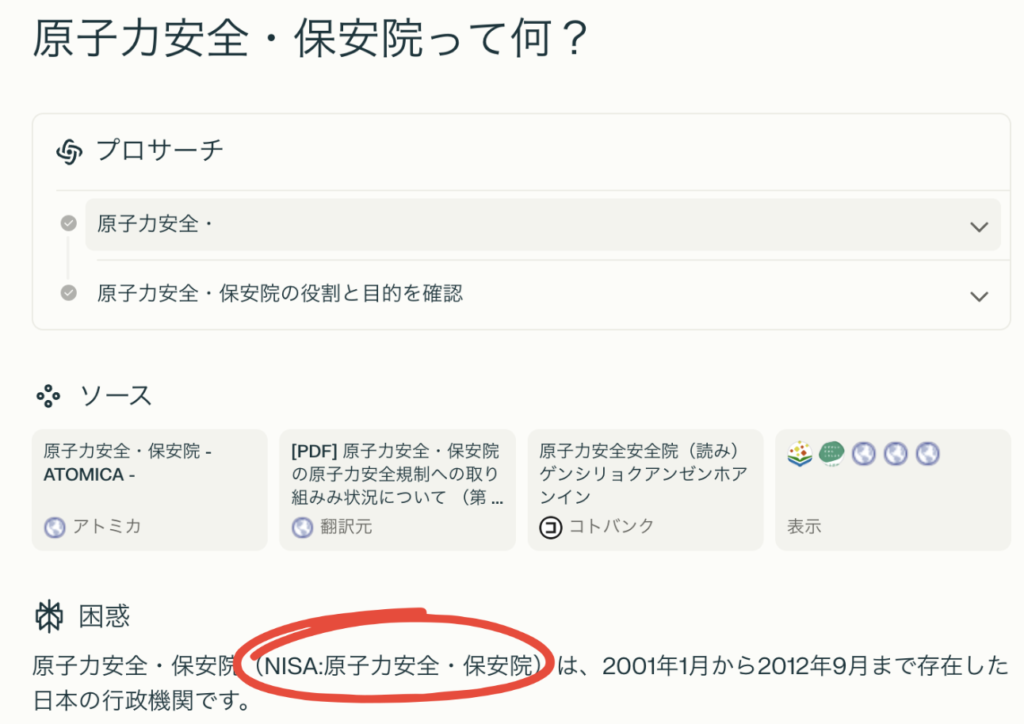
調べてみると、原子力安全・保安院という行政機関を略して「NISA」と呼ぶそうです。
このように、事実であるけど、今回欲しい情報ではないものも混在して回答してしまっているのがハルシネーションで見られる現象です。
こちらは一例ではありますが、事実確認の際にはファクトチェックのみでなく、冒頭から末尾まで文章の流れを確認し、ストーリーとして矛盾がないか・実際に欲しい情報が回答されているかを確認してください。
情報源の確認方法
AIの回答を裏付ける根拠が明示されていない場合、信頼性は不明瞭になってしまいます。
回答結果に関しては、統計資料、公式サイト、学術論文、専門家のコメントなど、正当性を担保する情報源があるかどうかをチェックしましょう。これは、人間が担当するファクトチェックの作業になりますね。
必要に応じて実際に該当する情報元を参照し、回答の正確性を検証することで、誤情報に惑わされるリスクを大幅に軽減できます。
上記の図はPerplexityですが、他にGensparkなど、AIの種類によっては回答の根拠となるサイトや文献を表示してくれるものがあります。こちらも参考にご自身の目で確かめてくださいね。
ビジネスでのAI活用における注意点
個人利用だけでなく、ビジネス利用にAIを活用したいですよね。今後、AIの運用が促進されていけば、業務効率化のみでなく、人手不足の解消も同時に図ることもできるため、企業にとってはコストメリットも高くなると考えられています。
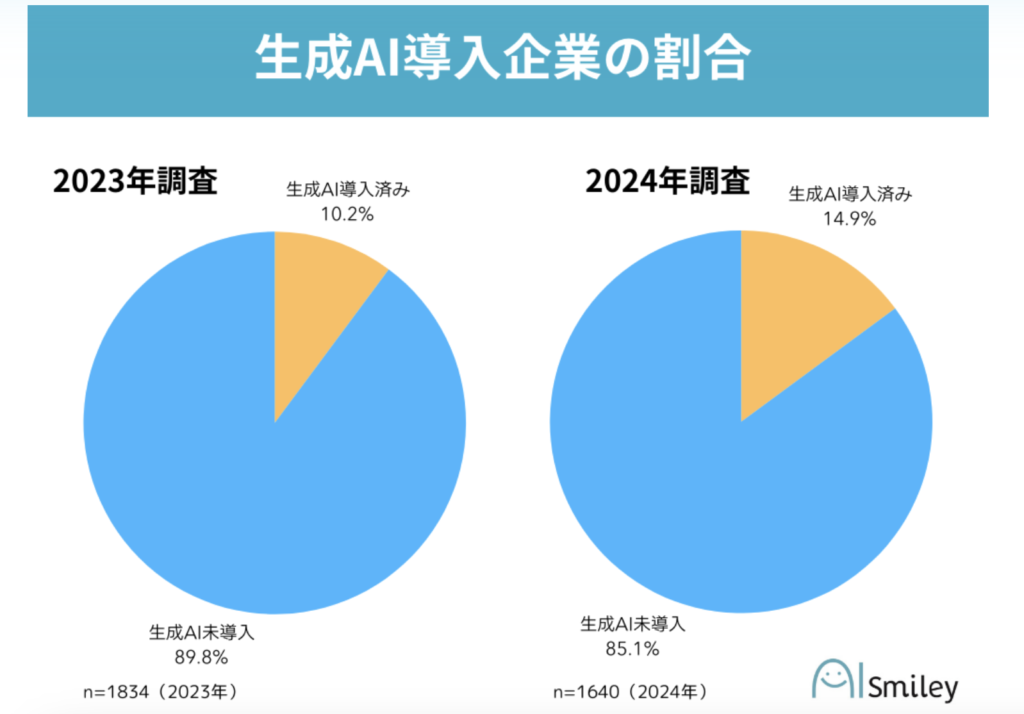
東証プライム企業への導入は、2023年から4.7ポイント増加しているものの、2024年時点で全体の14.9%にとどまっています。
なぜ、企業導入にはまだハードルが高いことが多いのでしょうか?どのような注意点があるか、その理由も含めて、確認してみましょう。
情報漏洩のリスク
AIシステムに入力したデータは、外部に漏れる可能性があるため、社内の機密情報や、個人情報を扱う際には慎重になる必要があります。
その理由として、生成AIは学習データとして入力された情報を利用する性質である、ということが大きいでしょう。企業にとって、開発途中や未発表のものなど、社内の資産となり得るものをAIが学習してしまうと、競合に知られてしまったり、犯罪に使われるリスクがあるなど、企業へのダメージが多いものをAIに任せられないため留意する必要があります。
とは言っても、作業や業務効率化を考えると、業務上で使いたくなりますよね。所属企業でのルールを確認して、適切にAIを活用していきましょう。
倫理的な問題
倫理的な問題も、AIを活用する上で必要な課題です。
倫理的な問題も課題視しなければいけない理由は、AIは学習データに基づいて判断を行うことにあります。そのデータに偏りがあると、人間の思いとは別に、不適切な判断や差別的なコンテンツを生成してしまうリスクに繋がってしまう、ということです。
特に、人種や性別に関する偏見等は、図らずも回答に反映されてしまう可能性があるため、出力結果の倫理性についても、しっかりと人間によるチェックをしていかなければならないですね。
AIのビジネス利用におけるリスク管理と対策
AIのビジネス利用では、データ不正利用やモデル悪用など、さまざまなリスクが生じます。
これらを抑えるためには、データ暗号化やアクセス管理、法規制の遵守、人材教育、内部監査といった総合的な対策が不可欠です。
1.データ不正利用の例:
ある企業が顧客データを使ってAIモデルを活用しているとします。
顧客データには個人名や住所、購買履歴などが含まれています。もし外部から不正アクセスを受けてこれらのデータが流出すれば、顧客情報が悪用される恐れがあります。
例えば、流出したデータがスパムメールやフィッシング詐欺などの可能性が出てきますね。また、これがさらに悪用されて、なりすまし犯罪などに使われてしまったら、企業の信用は大きく損なわれ、顧客の被害も大きくなってしまいます。
2. モデル悪用の例:
AIモデル自体が攻撃対象になるケースもあります。
たとえば、ある企業が、AIによる不正検知システムを導入している場合、悪意のある第三者が、そのモデルの弱点を見抜き、あえてモデルが検知しづらい手口で不正行為を行うということも考えられますね。
また、モデルを逆手に取って、顧客データやビジネス戦略の社外秘情報などの内部情報を抽出しようとする「モデル反転攻撃」も懸念されます。これにより、企業のノウハウや顧客セグメント情報が漏れる可能性も出てきてしまいます。
このような内容は、あくまで一例ですが、AIを活用する企業はこうしたリスクを想定し、セキュリティ対策やアクセス制御、データ管理の強化を行って、不正利用やモデル悪用を未然に防ぐことが求められます。
また、企業内にAI推進室のような部署を設けて、定期的なモデル検証・更新によりセキュリティ体制を強化し、長期的な信頼性を維持することも有効で、このような企業が増えています。
企業内でAIを採用する場合は、ネットサーバーやクライアントPCのみでなく、AIに対しても取り組みを強化すると、今後のビジネス価値の拡大と顧客信頼の確保につながります。
まとめ
今回は、AIにおける嘘(ハルシネーション)を中心に、その理由の解説と、ビジネスシーンにおける対策についてもご紹介しました。
情報化が加速する日本で、AIを活用することで業務効率化や人で不足の確保、個人でもさまざまなシーンで有用性が発揮できます。
AIの性質を理解しながら、人間でしかカバーできない分野を補って新しい価値を生み出せるようにしていきたいですね。







