
AmazonのアシスタントAI「アレクサ」や、Apple製品のアシスタントAI「Siri」など、身近なところに音声認識は使われています。そのため、一度は利用したことがある人がほとんどではないでしょうか。この記事では、音声認識とはどのようなものなのか、アシスタントAI以外にどのような活用事例があるのか、そして音声認識を活用するメリットについても解説していきます。
音声認識とは?
音声認識は、人の発する言葉を認識し、音声データをテキスト化する技術のことです。音声認識は、言葉をそのまま文字通りインプットするため、解析が機械的です。そのため、曖昧な言葉のニュアンスまでは理解しきれないこともあります。
そこで、曖昧性を理解する自然言語処理の技術を組み合わせて使うことで、音声認識はより高度な解析が可能になります。自然言語の曖昧性とは、状況が特定しづらい表現のことです。例えば「頭の上」という言葉の場合、頭に直接載っている状態のことを指すのか、頭の上の空間のことを指すのかわかりづらいですよね。
私も、音声認識の翻訳機能を使った際、テキスト化した際に「てにをは」の「は」と通常の「はひふへほ」の「は」を認識間違いされてしまった経験があります。日本語の曖昧性と外国語の曖昧性による誤認識で、外国語翻訳がおかしな内容になってしまうのを経験したことがある人も多いのではないでしょうか。
このような自然言語の曖昧性を理解し、解析できる技術を合わせることで、音声認識を活用したAIの機能は精度を上げ続けているのです。
音声認識の流れ
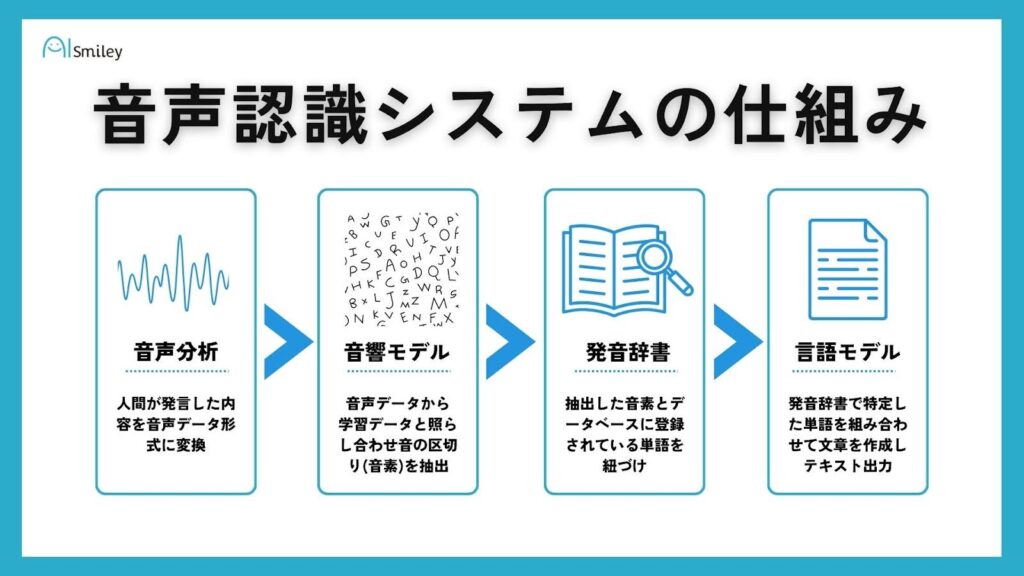
AISmily
音声データを、テキスト化する際に経る工程は4つです。音声データのテキスト化は「デコーディング」と呼ばれ、デコーディングの工程は「音響分析」「音響モデル」「発音辞書」「言語モデル」とそれぞれ呼ばれています。デコーディングとは本来コード化された変換後のデータを復元することを言います。
音声認識においては、一度データ化された音声を人の話す言葉として復元する作業を重要視しているため、ただのデータ化ではなくデコーディングという言葉が使われているのです。ここからは、デコーディングの各工程を1つずつ解説していきます。
音響分析
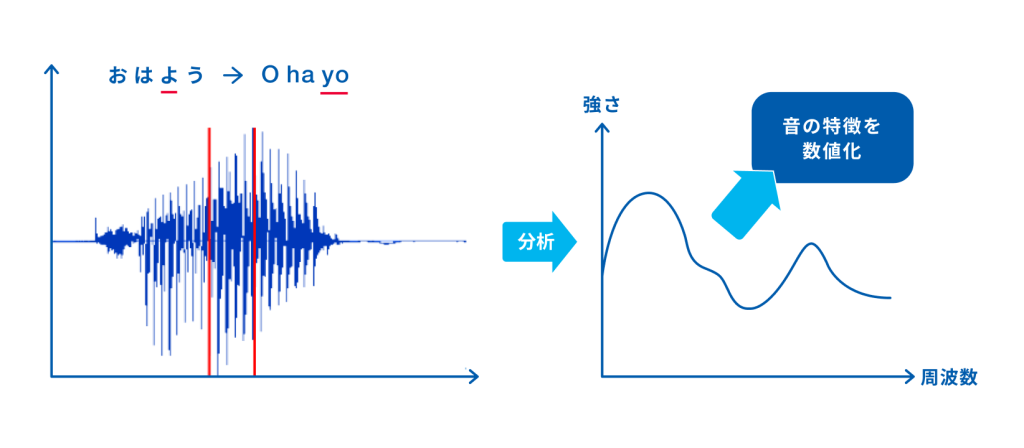
株式会社アドバンストメディア
音響分析は、入力した音声の周波数や音の強弱を調べて必要なものを抽出し、AIが認識できるデータへと変換する作業です。この音声の周波数や、音の強弱から抽出した特徴を数値化したものは、特徴量と呼ばれています。
アナログ信号である音声はAIには認識できないため、認識しやすいようにデジタル化する必要があるのです。音声をデジタル化する際、音素が抽出され、ノイズキャンセリングが行われます。音素とは、例えば「ぱ」と「ば」の音を違う音と認識するように、意味の違いに関わる最小の音声的な単位のことを言います。
音響モデル
音響モデルとは、先ほどの音響分析の際に出てきた「音素の抽出」作業です。音響分析でデータ化した特徴量を、AIが持つデータと照らし合わせ、特徴量がどの音素と近いのかを見つけます。
音響モデルでは、「隠れマルコフモデル」という確率過程が主な手法として使われています。隠れマルコフモデルとは、マルコフ性という確率論における特性と、確率変数のモデルの一つである確率過程の両方を満たしている音響モデルです。
マルコフ性は、将来の状態の決定を現在の状態にのみ依存し、過去の状態には依存しない特性を指します。確率過程とは、時間などの条件によってランダムに変動する確率変数を数学的に記すモデルです。確率過程は、株や為替の変動、感染症の流行などを数値化するのに使われています。
マルコフモデルは、状態が確率によって変遷していくのを表現するのに対し、隠れマルコフモデルは状態を直接観測しません。したがって、状態が変わったことによって発生した事象のみが観測でき、その事象から隠れた状態を把握することを言います。
音素と発音辞書の連結
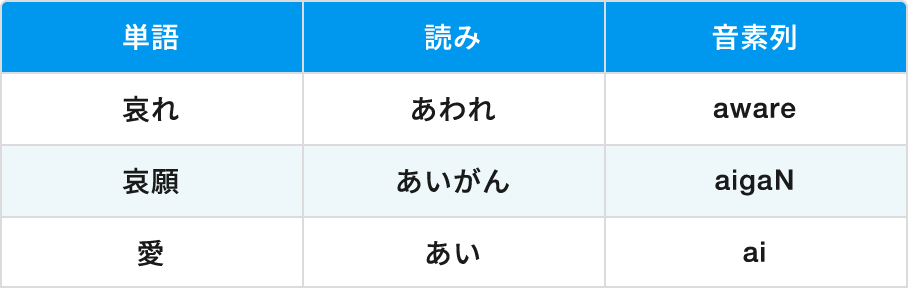
株式会社アドバンストメディア
次に、音素と発音辞書を連結させ、単語として組み立てていきます。例えば「a-s-o-b-u」という音素を「あそぶ」と認識させていくような作業です。発音辞書とは、音響モデルで抽出した音素が、どの単語と近いか照らし合わせるデータベースのことを言います。
発音辞書には、「遊ぶ」なら「asobu」、「寝る」なら「neru」など、単語の読み方が音素の並びで大量に登録されています。音素を抽出する時点で誤りが発生した場合は、人により手動で正しい単語に変えることもあります。音響モデルでは、AIに数千人、数千時間の音声を使ったデータを事前学習させていますが、正確とは言い切れないのです。
言語モデル
先述の音素と発音辞書の連結は、単語を組み立てただけであり、文章としては成り立っていません。言語モデルとは、発音辞書で見つけた単語や品詞の出現頻度モデルのことです。音声認識の流れにおいては、単語を出現する頻度が高い文章に組み立てることを言います。
言語モデルの手法として主に使われているのはN-gramモデルです。テキスト内のN個の文字列や単語の組み合わせが、どの程度出現するかを調査します。隣り合った単語の組み合わせを共起関係と言い、その共起関係がどのくらいの頻度で現れるかの集計結果を共起頻度と言います。
文章の学習データを大量に集め、この共起頻度を記録しているため、可能性が高い単語の組み合わせや、意味がある文章が作られるのです。
活用事例
- 議事録の作成
- 翻訳機能
- 異音検知
音声認識は、実際にはどのような場面で活用されているのでしょうか。音声認識は音声をテキスト化するため、人の会話の迅速なテキスト化が望まれるシーンで重宝される技術です。ここからは、音声認識の活用事例を紹介していきます。
議事録の作成
議事録の作成は、私も事務職時代に経験がありますが、簡単なようで非常に大変な作業です。私の場合、会話のペースについていけず聞き逃してしまったり、逆に会話に集中してしまい書き逃してしまうことがよくありました。音声認識による議事録の作成は、このような聞き逃しや書き逃しがありません。
音声をそのまま拾ってすぐにテキスト化するため、ミスがなくリアルタイムで議事録を作成することができます。また、議事録を作成する社員は議事録に集中するため、会議には参加できません。議事録を音声認識で作成することで、会議に参加できる社員も増え、生産性も高まるでしょう。
翻訳
音声認識による翻訳機能は、一度利用したことがある人も多いのではないでしょうか。私も、道案内のときや接客の時に利用したことがあります。日本語で伝えたいことを機械に向かって話せば、その場で相手の言語でテキスト化してくれるため、それを相手に読んでもらえばコミュニケーションが成立します。
スマホの翻訳アプリなどが出始めたころは、音声の読み取り間違いや素人の私でもおかしな英語になっているのがわかるようなミスもありました。ですが、今ではかなり正確な翻訳アプリが増えたように思います。音声認識による翻訳技術も昔に比べて精度がかなり上がっていると感じます。
また、私は海外アーティストのファンですが彼らのインタビューや動画コンテンツがyoutubeに投稿された際、彼らの母国語を聞き取れなくても、音声を流しながらその場で翻訳する機能があるのは非常に便利です。
音声認識による翻訳機の向上により、一般での利用だけでなくビジネスでも利用しやすくなり、外国語を扱う職種でも、外国語スキルを社員に求める必要がなくなりました。社員が外国語の習得に割いていた時間を、他の作業に充てられたり、人事採用の際も外国語スキルがなくても他で専門的な知識がある人材を選ぶことができます。
異音検知
人の言葉のテキスト化だけでなく、機械や物の音を認識するような事例もあります。音声認識による異音探知は、正常に動いている機械や生物の音と、異常があるときの音をAIに学習させ、異常の早期発見が可能です。
機械類は故障してから買い替えることが多いと思いますが、そうすると代替品が無い場合、修理や新しいものを買い替えるまで機械を使えなくなってしまいますよね。音声認識による異音探知ができると、異常を見つけやすく早めに手を打てるのでスムーズに新しいものと交換できます。
機械だけでなく生体の異音探知は、重大な疾病を早期発見できるため、重宝される技術です。職人や医者の耳による聴診だけに頼ることなく、正確性の高い判断が可能になります。
音声認識を活用するメリット
- 手入力が不要になる
- ヒューマンエラーを防げる
音声認識は様々なシーンで活用されているのがわかりましたが、どのようなメリットがあるのかも知っておきたいですよね。現代社会では、通信機器もメールやチャットなどテキストでのコミュニケーションが主流になり、音声の存在が薄くなっているのを感じます。
そんな中でも、音声認識だからこそ便利なことや、扱いやすいシーンがあります。それでは、音声認識を活用するメリットについて見ていきましょう。
手入力が不要になる
音声認識を活用する最大のメリットともいえるのが、手入力が不要になることです。音声をテキスト化する際に、手入力をすると、人の負担が大きくなります。音声を聞き取ることと入力することの2つの作業を同時に行うのは非常に難しい作業です。そのため、テキストの作成に時間がかかるなど作業効率も良くありません。
音声認識によるテキスト化やデータ化ができれば、その場でリアルタイムにデータを作成し、必要な人にもすぐに配布可能です。人手を入力作業に取られないため、作業効率は上がること間違いなしです。
また、既に体験したことがある人も多いかもしれませんが、アシスタントAIへの音声での指示も非常に便利です。私も手入力が面倒なときや、該当する漢字がわからないとき、手がふさがっているときなどに音声認識で検索することがあります。
アシスタントAIによっては電気をつけたり、音楽をかけたり、家族に頼むように声をかけるだけで、こちらが求める作業をしてくれます。
ヒューマンエラーを防止できる
人による入力作業は、音声の聞き取りミスや入力ミスが起きかねません。聞き取りと入力を同時にすれば、集中力も落ちてしまいミスも起きやすくなります。音声認識を活用すれば、このようなヒューマンエラーを防止できるため、修正の手間が省けます。
一方で、音声認識を正確に行うにはノイズの少ない場所で明瞭な言葉や単語が認識できる状態を準備しなくてはなりません。誤認識も起こりうるので、音声認識による作業と人による修正を組み合わせるとより正確なデータを作成できるでしょう。
とはいえ、ヒューマンエラーは従業員にとって「犯してはいけない」というプレッシャーになりやすく、指摘する人と指摘される人の間で人間関係にも影響を与えることがあります。そのため、多少の誤認識があっても音声認識を活用する方が、従業員の精神的負担は軽減されるのではないでしょうか。
まとめ
音声認識の流れや活用事例、そしてそのメリットについて紹介してきましたが、音声認識の技術が向上することにより、ハンズフリーで人と接するように機械と接することができるのは魅力的だなと思いました。これまで人の手作業で行っていたものを音声認識に任せて、人はもっとクリエイティブな作業に力を入れられることでしょう。
音声認識の活用により、日本の生産性が高まり、豊かな経済が生み出せるようになることを期待したいですね。







